HiveMQ Enterprise Extension for Kafka
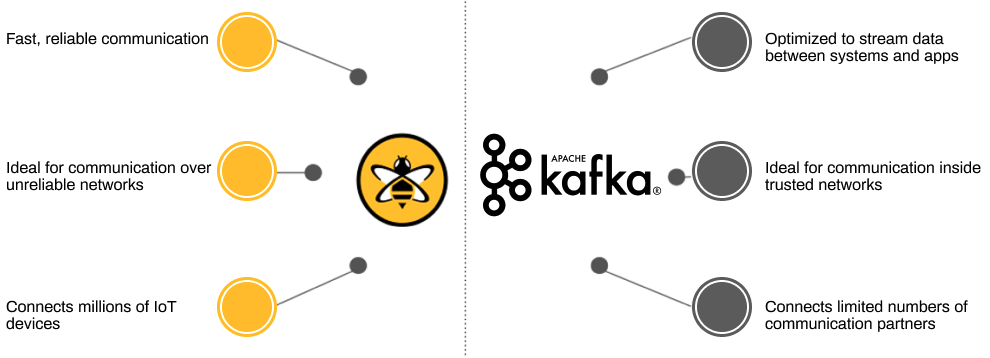
Apache Kafka is a popular open-source streaming platform that makes it easy to share data between enterprise systems and applications.
The HiveMQ Enterprise Extension for Kafka implements the native Kafka protocol inside your HiveMQ MQTT broker. This implementation solves the difficulty of using Kafka for IoT by seamlessly integrating MQTT messages into the Kafka messaging flow.
Use the HiveMQ Enterprise Extension for Kafka to add monitored, bi-directional MQTT messaging to and from your Kafka clusters for a highly-scalable and resilient end-to-end IoT solution.
Features
-
Forward MQTT messages from IoT devices that are connected to your HiveMQ MQTT broker to topics in one or more Kafka clusters.
-
Poll information from a Kafka topic and publish this information as MQTT messages to one or more MQTT topics.
-
Use placeholders to dynamically generate MQTT messages at runtime with values extracted from a Kafka record.
-
Use multiple MQTT topic filters with full support of wildcards to route MQTT messages to the desired Kafka topics.
-
Buffer messages on the HiveMQ MQTT broker to ensure high-availability and failure tolerance whenever a Kafka cluster is temporarily unavailable.
-
Monitor all MQTT messages that are written to and from Kafka on the centralized HiveMQ Control Center.
-
Validate messages that you read from Kafka with the help of a schema registry.
-
Use the HiveMQ Kafka Extension Customization SDK to programmatically specify sophisticated custom-handling of message transformations between HiveMQ and Kafka.
With the HiveMQ Enterprise Extension for Kafka, your HiveMQ MQTT broker can forward MQTT messages from multiple MQTT topic filters to as many Kafka topics as you choose. Conversely, the extension enables you to poll information from the records in a Kafka topic, extract the data you need, and publish the information to as many MQTT topics as your use case requires.
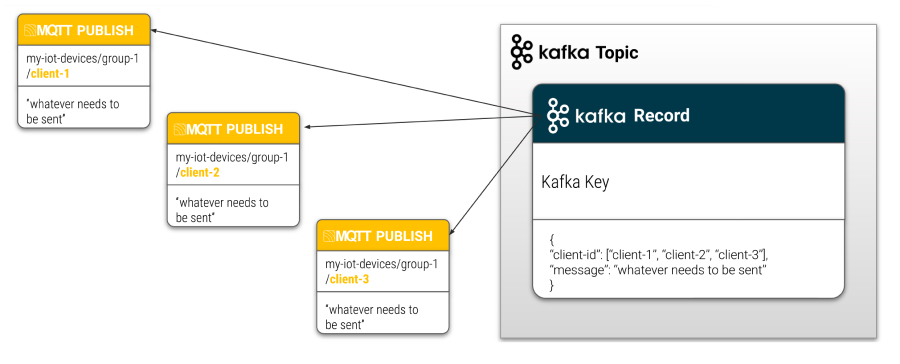
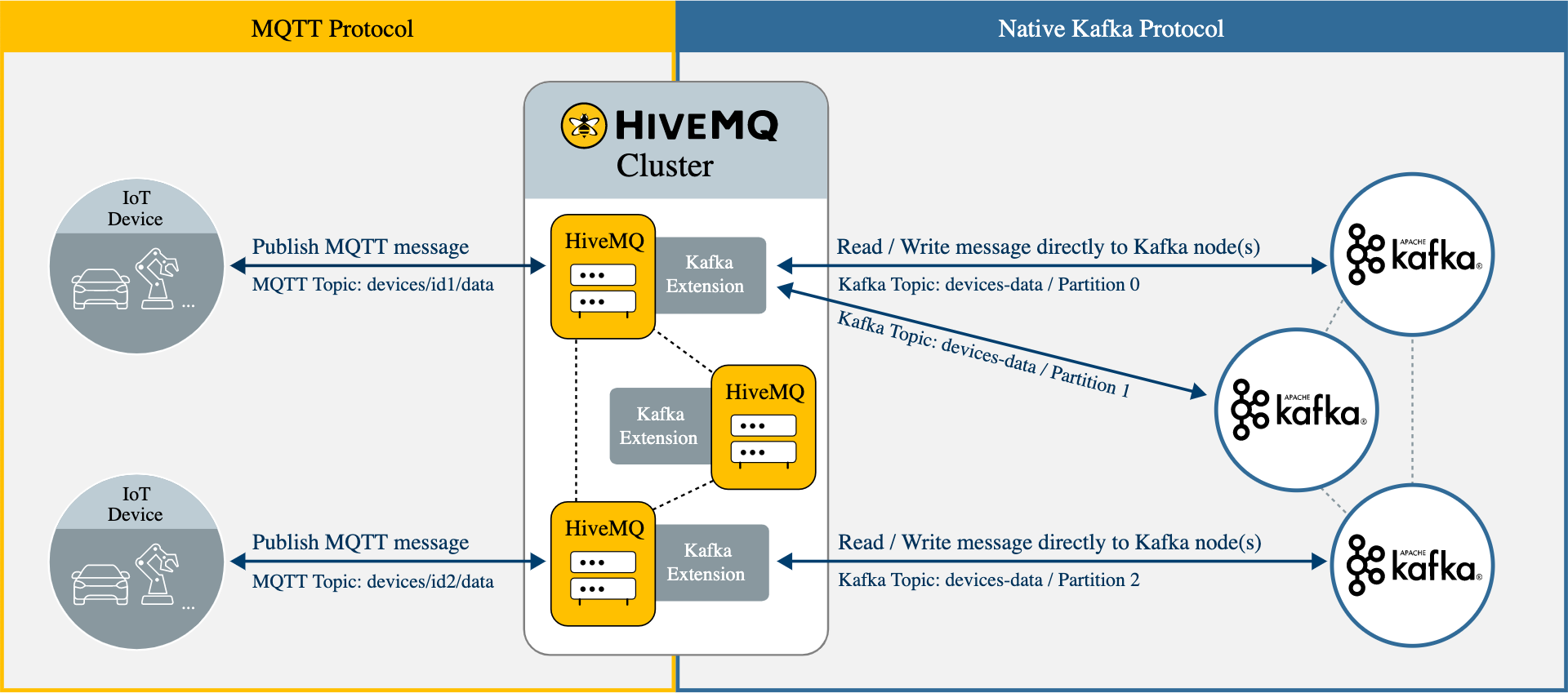
The MQTT-to-Kafka function of the HiveMQ Enterprise Extension for Kafka acts as multiple Kafka producers that route the selected MQTT publish messages to the desired Kafka topics. Each HiveMQ extension on every HiveMQ node in the HiveMQ cluster automatically opens connections to all Kafka brokers that are needed in the desired Kafka clusters.
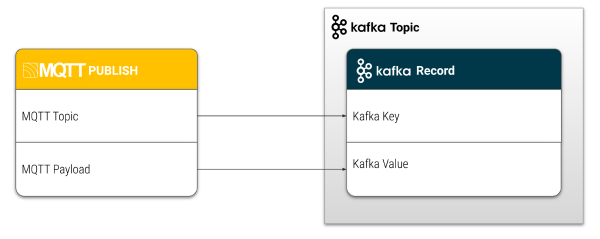
HiveMQ sends the MQTT messages that are published to the selected MQTT topic to Kafka with the original MQTT topic from the publish message as Kafka key and the payload of the MQTT publish message as the Kafka value.
The Kafka-to-MQTT function of the extension makes it possible to transform Kafka records and publish values that are extracted from the different areas of the Kafka topic in new MQTT messages. There are many ways to configure how HiveMQ uses the information from Kafka. All HiveMQ Enterprise Extensions for Kafka in a HiveMQ cluster work together as a consumer group to balance the workload and retrieve data from an individual Kafka topic.
By default, the Kafka topic is used as the MQTT topic and the Kafka value is the MQTT payload.
| The in-order guarantee of Kafka records is per partition on a Kafka topic. This order is preserved for the MQTT Client that receives the created MQTT publishes. |
The ability to multicast targeted MQTT messages from individual records in a Kafka topic is attractive for a wide range of possible use cases. For example, to collect event information from particular services in a Kafka topic, listen to the Kafka topic, and react with dynamically generated MQTT messages to the appropriate MQTT topics.
Since the HiveMQ extension manages both the MQTT-to-Kafka and the Kafka-to-MQTT functions, you can easily maintain a clear overview of all communication from the Control Center of your HiveMQ broker.
| The HiveMQ Enterprise Extension for Kafka does not interfere with the publish/subscribe mechanism of MQTT and can be used in addition to normal MQTT subscriptions and shared subscriptions. |
Requirements
-
A running HiveMQ Platform
-
A running Kafka Cluster (versions 2.1 and higher)
-
A valid license for the HiveMQ Enterprise Extension for Kafka.
| If you do not provide a valid license, HiveMQ uses a free trial license automatically. The trial license for the HiveMQ Enterprise Extension for Kafka is valid for 5 hours. For more license information or to request an extended evaluation license, contact HiveMQ sales. |
Installation
-
Place your HiveMQ Enterprise Extension for Kafka license file (.elic) in the license folder of your HiveMQ installation. (Skip this step if you are using a trial version of the extension. For information on evaluation limits, see HiveMQ website.)
The HiveMQ Enterprise Extensions are preinstalled in your HiveMQ release bundle and disabled.└─ <HiveMQ folder> ├── README.txt ├── audit ├── backup ├── bin ├── conf ├── data ├── extensions │ ├── hivemq-kafka-extension │ │ ├── conf │ │ │ ├── config.xml (needs to be added by the user) │ │ │ ├── config.xsd │ │ │ └── examples │ │ │ └── ... │ │ ├── hivemq-kafka-extension.jar │ │ ├── hivemq-extension.xml │ │ └── third-party-licenses │ │ └── ... ├── license ├── log ├── third-party-licenses └── tools -
Before you enable the extension, you need to configure the extension for your individual Kafka clusters and Kafka topics. For your convenience, we provide an example configuration
conf/examples/config.xmlthat you can copy and modify as desired.
The includedconfig.xsdfile outlines the schema and elements that can be used in the XML configuration.
Your completed configuration file must be namedconfig.xmland located atHIVEMQ_HOME/extensions/hivemq-kafka-extension/conf/config.xml.
For information on all your configuration options, see Configuration. -
To enable the HiveMQ Enterprise Extension for Kafka, locate the
hivemq-kafka-extensionfolder in theextensionsdirectory of your HiveMQ installation and remove theDISABLEDfile. -
To verify that the extension is installed and configured properly, check the HiveMQ logs and the newly-created Kafka tab that is added to your HiveMQ Control Center.
| To function properly, the HiveMQ Enterprise Extension for Kafka must be installed on all HiveMQ broker nodes in a HiveMQ cluster. |
If any of the configured Kafka topics do not already exist, the HiveMQ Enterprise Extension for Kafka attempts to create the topic automatically.
The topic is created with a default replication factor of 1 and a default partition count of 10.
|
Configuration
The HiveMQ Enterprise Extension for Kafka supports hot reload of your extension configuration. Changes that you make to the configuration of the extension are updated while the extension is running, without the need for a restart.
The HiveMQ Enterprise Extension for Kafka is preconfigured with sensible default settings. These default values are usually sufficient to get you started.
Configuration of the extension is divided into four sections:
-
Kafka Clusters: General information and connection settings for one or more Kafka clusters.
-
MQTT-to-Kafka Mappings: Routing information for one or more MQTT topic filters to a Kafka topic.
-
Kafka-to-MQTT Mappings: Routing information for one or more records in a Kafka topic to one or more MQTT topics.
-
Schema Registry: Schema used to deserialize values in the Kafka topic.
Each mapping refers to exactly one Kafka cluster. However, a single Kafka cluster can use multiple mappings.
Schema Validation of the Extension Configuration File
The Kafka extension gives you the option to activate schema validation for the config.xml configuration file of your extension.
Currently, schema validation is disabled by default.
The schema validation uses the provided config.xsd file to validate the config.xml before it is used by the extension.
Schema validation catches configuration issues that the extension does not detect programmatically.
For example, tags with invalid or misspelled names are detected with the schema validation. Duplicate tags result in ambiguous behavior depending on which of the values is parsed. For optional tags these configuration errors often go unnoticed without schema validation enabled.
| We recommend to activate schema validation to highlight possible configuration issues. |
You can enable the schema validation behavior in two ways:
-
Add a line with the following Java system property to your
bin/run.shfile:JAVA_OPTS="$JAVA_OPTS -Dhivemq.extensions.kafka.config.skip-schema-validation=false" -
Provide the environment variable:
export HIVEMQ_EXTENSIONS_KAFKA_CONFIG_SKIP_SCHEMA_VALIDATION=false
The provided config.xsd file can be used with XML editors and IDEs that have schema support to add helpful content completion assistance for your XML configuration.
|
Configuration File
The config.xml file is located in HIVEMQ_HOME/extensions/hivemq-kafka-extension/conf/config.xml.
The extension uses a simple but powerful XML based configuration.
If you want to copy and reuse the example configuration, be sure to move the file to conf/config.xml before you enable your extension.
|
<?xml version="1.0" encoding="UTF-8" ?>
<kafka-configuration xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="config.xsd">
<kafka-clusters>
<kafka-cluster>
<id>cluster01</id>
<bootstrap-servers>127.0.0.1:9092</bootstrap-servers>
</kafka-cluster>
</kafka-clusters>
<mqtt-to-kafka-mappings>
<mqtt-to-kafka-mapping>
<id>mapping01</id>
<cluster-id>cluster01</cluster-id>
<mqtt-topic-filters>
<mqtt-topic-filter>mytopic/#</mqtt-topic-filter>
</mqtt-topic-filters>
<kafka-topic>my-kafka-topic</kafka-topic>
</mqtt-to-kafka-mapping>
</mqtt-to-kafka-mappings>
<kafka-to-mqtt-mappings>
<kafka-to-mqtt-mapping>
<id>mapping02</id>
<cluster-id>cluster01</cluster-id>
<kafka-topics>
<kafka-topic>first-kafka-topic</kafka-topic>
<kafka-topic>second-kafka-topic</kafka-topic>
<!-- Arbitrary number of Kafka topics -->
</kafka-topics>
</kafka-to-mqtt-mapping>
</kafka-to-mqtt-mappings>
</kafka-configuration>
All HiveMQ Enterprise Extensions support the use of environment variables.
The ${ENV:VARIABLE_NAME} pattern allows you to add placeholders to your configuration xml file that are replaced with the value of an environment variable at runtime.
Environment variables cannot be hot reloaded.
You must set your environment variables before HiveMQ startup.
For more information, see Environment Variables.
|
You can apply changes to the config.xml file at runtime.
There is no need to restart the extension or HiveMQ for the changes to take effect (hot reload).
The previous configuration file is automatically archived to the config-archive subfolder in the extension folder.
| If you change the configuration file at runtime and the new configuration contains errors, the previous configuration is kept. |
When configuration changes at runtime, topic mapping pauses, and restarts automatically to include the changes.
When a topic mapping restarts, the existing connections to Kafka for the topic mapping are closed and re-established.
If only the mqtt-topic-filters in a topic mapping change, no restart of the topic mapping is required.
Kafka Cluster
The extension uses the <kafka-cluster> settings to establish the connection to a Kafka cluster.
<kafka-clusters>
<kafka-cluster>
<id>cluster01</id>
<bootstrap-servers>127.0.0.1:9092</bootstrap-servers>
</kafka-cluster>
</kafka-clusters>The following <kafka-cluster> values can be configured:
| Name | Default | Mandatory | Description |
|---|---|---|---|
|
- |
The unique identifier of the Kafka cluster. This string can only contain lowercase alphanumeric characters, dashes, and underscores. |
|
|
- |
The comma-separated list of the Kafka bootstrap servers with host and port. |
|
|
disabled |
Optional TLS configuration for the Kafka cluster. For more information, see TLS configuration. |
|
|
none |
Optional authentication configuration for the Kafka cluster. For more information, see Authentication configuration. |
If you need to connect to the same Kafka cluster with different settings, simply add the same cluster multiple times with a different id and different settings.
|
Topic Mapping & Message Processing
MQTT-to-Kafka Topic Mapping
MQTT-to-Kafka mappings represent the routing information from MQTT topic filters to Kafka topics. The mapping from MQTT to Kafka is relatively simple. You select the Kafka Topic on which you want to publish the MQTT Topic. The MQTT Topic is used as the Kafka Key and the MQTT Payload is used as the Kafka Value.
<mqtt-to-kafka-mappings>
<mqtt-to-kafka-mapping>
<id>mapping01</id>
<!-- Kafka cluster to use for this topic mapping -->
<cluster-id>cluster01</cluster-id>
<!-- List of MQTT topic filters -->
<mqtt-topic-filters>
<mqtt-topic-filter>topic1/#</mqtt-topic-filter>
<mqtt-topic-filter>topic2/#</mqtt-topic-filter>
</mqtt-topic-filters>
<!-- Target Kafka topic -->
<kafka-topic>topic01</kafka-topic>
<!-- 100 * 1024 * 1024 = 104857600 = 100 MiB-->
<kafka-max-request-size-bytes>104857600</kafka-max-request-size-bytes>
</mqtt-to-kafka-mapping>
</mqtt-to-kafka-mappings>The following <mqtt-to-kafka-mapping> values can be configured:
| Name | Default | Mandatory | Description |
|---|---|---|---|
|
- |
The unique identifier of the |
|
|
- |
The identifier of the referenced Kafka cluster. |
|
|
- |
The list of one or more MQTT topic filters.
|
|
|
- |
The destination Kafka topic to which the configured MQTT messages are routed. |
|
|
|
The Kafka acknowledgment mode. This mode specifies the way that the Kafka cluster must acknowledge incoming messages. Three Kafka acknowledgment modes are available:
For more information, see Kafka Producer acks. |
|
|
1 MB |
Optional setting to define the maximum size in bytes that a request to Kafka can contain. This value determines the largest MQTT message size that you can send to Kafka, and must be an integer greater than 0. The default value is 1 MB. This setting defines the NOTE: The maximum size the MQTT protocol allows in a single MQTT publish message is 256 MB. |
|
|
- |
The list of Kafka record headers. The headers can be static text or dynamic values from the mapped MQTT message.
NOTE: To insert content dynamically in a Kafka record header, replace the Possible placeholders for the record header value are: NOTE: Similar to MQTT user properties, multiple headers with the same key can be added. |
|
|
|
The Kafka partition distribution strategy. The strategy determines how MQTT messages are distributed across multiple partitions of a Kafka topic.
NOTE: The |
The default maximum message size that Kafka brokers accept is 1 MB.
If you configure the kafka-max-request-size-bytes to forward MQTT messages that are larger than 1 MB to Kafka, check that the maximum message size of your Kafka broker is adjusted accordingly.
|
If you want to send the same messages to multiple Kafka topics, simply duplicate the topic mapping and change the id and the kafka-topic of the additional topic mappings.
|
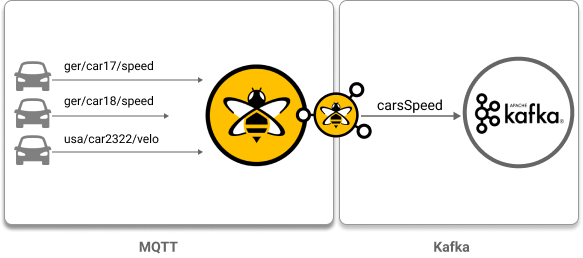
Example MQTT to Kafka Use Case
Map multiple MQTT topics to one Kafka topic: In this use case, the goal is to send messages from millions of connected cars (MQTT clients) to one Kafka topic.
<mqtt-to-kafka-mappings>
<mqtt-to-kafka-mapping>
<id>many-to-one-mapping</id>
<cluster-id>cluster-local-1</cluster-id>
<mqtt-topic-filters>
<mqtt-topic-filter>ger/+/speed</mqtt-topic-filter>
<mqtt-topic-filter>usa/+/velocity</mqtt-topic-filter>
</mqtt-topic-filters>
<kafka-topic>carsSpeed</kafka-topic>
<kafka-record-headers>
<kafka-record-header>
<key>static-text-header</key>
<value>my-fixed-value</value>
</kafka-record-header>
<kafka-record-header>
<key>dynamic-mqtt-content-type-header</key>
<mqtt-content-type/>
</kafka-record-header>
</kafka-record-headers>
</mqtt-to-kafka-mapping>
</mqtt-to-kafka-mappings>Kafka-to-MQTT Topic Mapping
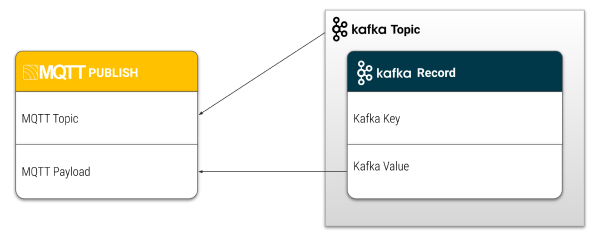
Kafka-to-MQTT mappings represent the routing information from Kafka topics to MQTT topics. Information from the Kafka record is sent on the MQTT topics that you define in the configuration.
If no MQTT topic is set, the Kafka topic is used as the MQTT topic. Unless otherwise configured, the payload of the MQTT message is the value of the Kafka record:
Each Kafka-to-MQTT topic mapping in the Kafka Extension has a dedicated Kafka consumer. In the HiveMQ cluster, all Kafka consumers for the same topic mapping are combined in one consumer group. The number of Kafka-to-MQTT topic mappings equals the number of consumer groups.
The HiveMQ Enterprise Extension for Kafka automatically assigns a consumer group name to each Kafka-to-MQTT topic mapping that you create.
The consumer group name consists of the following information:
hivemq- + mappingID + -group.
For example, the extension automatically assigns a topic mapping with the topic mapping ID topic-mapping-1 the consumer group name hivemq-topic-mapping-1-group.
Verify that the permissions on your Kafka cluster allow consumer group name patterns that begin with hivemq.
|
| If your architecture uses multiple HiveMQ clusters to consume identical topics from a single Kafka cluster, your HiveMQ topic mapping IDs must be unique across all HiveMQ clusters to ensure all clusters consume all messages. |
The extension reads and processes Kafka records in batches. The offset of the last record of each processed batch is committed to Kafka as soon as the batch is processed. This method ensures continuity if an extension in the cluster is temporarily unavailable or any other rebalancing of the cluster occurs.
After a restart, or when one node leaves the cluster and another node takes over, the extension continues reading from the point where it stopped before the restart.
| Since each partition in your Kafka topic has one dedicated consumer, it is a best practice to have more partitions than Kafka extensions (consumers). This configuration option for the Kafka topic ensures higher efficiency and maximum utilization of your HiveMQ extension. |
To increase practical usability and fulfill a wide range of use cases, it is possible to extract information from the Kafka value. To enable the extraction of information, the Kafka value must be deserialized by the HiveMQ Enterprise Extension for Kafka. Supported information formats are listed here. The information can be extracted with a semantic that is similar to XPath. For more information, see supported path syntax.
<kafka-to-mqtt-mappings>
<kafka-to-mqtt-mapping>
<!-- The ID is used for logging messages -->
<id>mapping01</id>
<!-- Kafka cluster to use for this topic mapping -->
<cluster-id>cluster02</cluster-id>
<!-- List of kafka topics -->
<kafka-topics>
<kafka-topic>topic1</kafka-topic>
<kafka-topic>topic2</kafka-topic>
</kafka-topics>
</kafka-to-mqtt-mapping>
</kafka-to-mqtt-mappings>In the minimal configuration example, the MQTT topic of the MQTT publish messages defaults to the Kafka topic and the MQTT payload defaults to the Kafka value.
The following <kafka-to-mqtt-mapping> values can be configured:
| Name | Default | Mandatory | Type in Path | Description |
|---|---|---|---|---|
|
- |
- |
The unique identifier of the |
|
|
- |
- |
The identifier of the referenced Kafka cluster. |
|
|
- |
- |
The list of one or more Kafka topics or Kafka-topic patterns the consumer subscribes to.
NOTE: Be careful when using |
|
|
none |
- |
Specifies whether the Kafka records are deserialized.
|
|
|
|
String-Array |
The list of one or more MQTT topics to which the messages are sent.
|
|
|
|
Bytes, other |
The payload for the MQTT messages. If no schema is applied, the original Kafka value is sent as the MQTT payload and cannot be modified. |
|
|
- |
- |
The metadata that is defined for the MQTT publish message. For more information, see MQTT Publish Fields. |
| If you use a schema registry, we do not recommend the use of Kafka topic patterns. The combination of Kafka topic patterns and a schema registry can cause unexpected behavior that is difficult to interpret. |
|
When you use a JSON schema, you can select a byte array type for the Encode your payload as a base64 string. In the JSON schema, specify the type as `string` with an additional property `contentEncoding` set to `base64`. The Kafka extension decodes your Base64 string into a byte array when selected by the path syntax as the MQTT payload. The contentEncoding parameter is available since draft version 7 of the JSON schema.
Example payload field using byte arrays with JSON schema
|
MQTT Publish Fields
In the <mqtt-publish-fields> of the Kafka-to-MQTT configuration, you can specify the metadata of the MQTT Publish message that the mapping creates.
| Each MQTT Publish field in the configuration file can contain only one variable. |
| Name | Default | Mandatory | Type in Path | Description |
|---|---|---|---|---|
|
|
Boolean |
Defines whether all MQTT messages from the corresponding Kafka-to-MQTT mapping are retained. Possible values are:
If set to |
|
|
- |
String |
Sets the format of the payload of the corresponding Kafka-to-MQTT mapping. Possible values are:
|
|
|
- |
Long, Integer, or String |
A long value that indicates the lifetime in seconds of a published message. The value must be positive. |
|
|
- |
String |
Sets the response topic for the MQTT messages. |
|
|
- |
Bytes |
Sets the correlation data for the MQTT messages. This data is used to show to which request a response message belongs. If you insert the correlation-data directly into the config, which means you don’t use path-syntax to extract it, you have to encode it in Base64. |
|
|
- |
String |
Sets the list of one or more user properties for the MQTT messages.
|
|
|
- |
String |
Specifies the content type of the MQTT message. |
|
|
|
Long, Integer, or String |
Sets the Quality of Service (QoS) for the MQTT message. Possible values are:
|
<kafka-to-mqtt-mapping>
...
<mqtt-publish-fields>
<retained-flag>true</retained-flag>
<payload-format-indicator>UTF-8</payload-format-indicator>
<message-expiry-interval>10000</message-expiry-interval>
<response-topic>my/response/topic</response-topic>
<correlation-data>my/correlation/data</correlation-data>
<user-properties>
<user-property>
<key>key1</key>
<value>value1</value>
</user-property>
<user-property>
<key>key2</key>
<value>value2</value>
</user-property>
</user-properties>
<content-type>JSON</content-type>
<qos>2</qos>
</mqtt-publish-fields>
</kafka-to-mqtt-mapping>Example Kafka to MQTT Use Cases
Map multiple Kafka topics to one MQTT topic: In this use case, the goal is to send alert messages to multiple MQTT clients from a backend service that is connected to Kafka. With the HiveMQ Enterprise Extension for Kafka, as many Kafka topics as desired can be mapped to a single MQTT topic. Through the HiveMQ broker, MQTT clients can subscribe to a single MQTT topic to get all configured alerts.
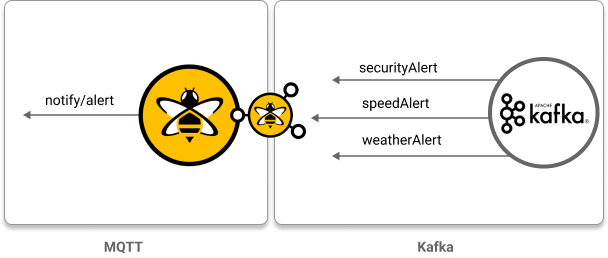
<kafka-to-mqtt-mappings>
<kafka-to-mqtt-mapping>
<id>mapping-01</id>
<cluster-id>cluster-local</cluster-id>
<kafka-topics>
<kafka-topic>securityAlert</kafka-topic>
<kafka-topic>speedAlert</kafka-topic>
<kafka-topic>weatherAlert</kafka-topic>
</kafka-topics>
<mqtt-topics>
<mqtt-topic>notify/alert</mqtt-topic>
</mqtt-topics>
</kafka-to-mqtt-mapping>
</kafka-to-mqtt-mappings>Multicast one Kafka topic to several MQTT topics: In this use case, the goal is to send updates from a backend system that utilizes Kafka to several models of an IoT wearable device (MQTT clients).
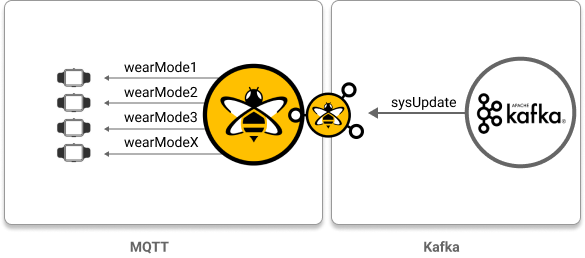
<kafka-to-mqtt-mappings>
<kafka-to-mqtt-mapping>
<!-- The ID is used for logging messages -->
<id>mapping01</id>
<!-- Kafka cluster to use for this topic mapping -->
<cluster-id>cluster01</cluster-id>
<!-- Kafka topic from which you are casting -->
<kafka-topics>
<kafka-topic>sysUpdate</kafka-topic>
</kafka-topics>
<!-- Multiple MQTT topics-->
<mqtt-topics>
<mqtt-topic>wearMode1</mqtt-topic>
<mqtt-topic>wearMode2</mqtt-topic>
<mqtt-topic>wearMode3</mqtt-topic>
<mqtt-topic>wearModeX</mqtt-topic>
</mqtt-topics>
</kafka-to-mqtt-mapping>
</kafka-to-mqtt-mappings>Use Kafka constants to efficiently map one Kafka topic to one or more MQTT topics: In this use case, the goal is to map information from a backend system that utilizes Kafka to a large number of connected cars (MQTT clients).
The kafka-key contains the MQTT topic.
The kafka-value uses all information that is included in the value of the Kafka record as the payload of the MQTT message.
At runtime, Kafka constant placeholders are replaced with the corresponding values from the Kafka record to create the appropriate MQTT messages for each connected car (MQTT client).
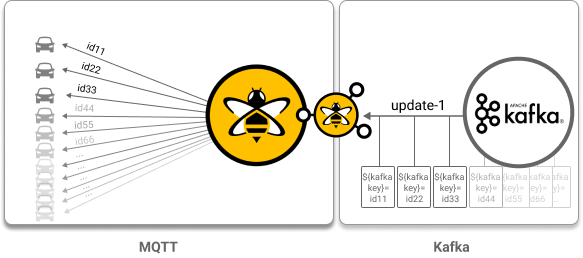
<kafka-to-mqtt-mappings>
<kafka-to-mqtt-mapping>
<!-- The ID is used for logging messages -->
<id>mapping03</id>
<!-- Kafka cluster to use for this topic mapping -->
<cluster-id>cluster03</cluster-id>
<!-- Kafka topic from which you are casting -->
<kafka-topics>
<kafka-topic>update-1</kafka-topic>
</kafka-topics>
<!-- Multiple MQTT topics-->
<mqtt-topics>
<mqtt-topic>${KAFKA_KEY}</mqtt-topic>
</mqtt-topics>
<mqtt-payload>${KAFKA_VALUE}</mqtt-payload>
</kafka-to-mqtt-mapping>
</kafka-to-mqtt-mappings>In this use case, the goal is to send an identical section of information to multiple IoT devices from a backend system that utilizes Kafka. Path syntax is used to extract specific parts of data from a deserialized Kafka record. This method requires the use of a schema registry.
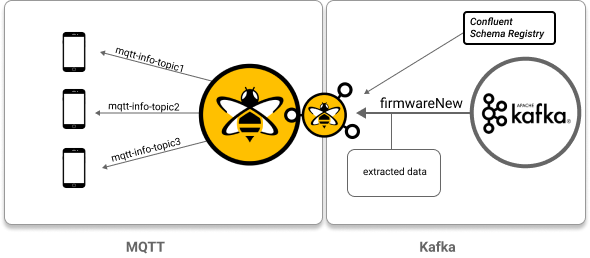
<kafka-to-mqtt-mappings>
<kafka-to-mqtt-mapping>
<!-- The ID is used for logging messages -->
<id>mapping03</id>
<!-- Kafka cluster to use for this topic mapping -->
<cluster-id>cluster03</cluster-id>
<!-- the schema registry to use to deserialize this Kafka topic -->
<use-schema-registry>confluent</use-schema-registry>
<!-- Kafka topic from which you are casting extracted information -->
<kafka-topics>
<kafka-topic>firmwareNew</kafka-topic>
</kafka-topics>
<!-- An array of MQTT topics -->
<mqtt-topics>
<mqtt-topic>${//mqtt-info/topic}</mqtt-topic>
</mqtt-topics>
<!-- The information that is sent from the Kafka record -->
<mqtt-payload>${//mqtt-info/data}</mqtt-payload>
</kafka-to-mqtt-mapping>
</kafka-to-mqtt-mappings>Schema Registries
Kafka itself does not check the format of a message or verify message correctness.
The use of one or more schema registries can ensure proper messaging functionality and provide message validation. For example, when you receive a message from Kafka and want to forward the message through HiveMQ, you can validate the message with a schema. If the message format is invalid and does not fit the specified schema, the HiveMQ broker does not publish the message.
A schema registry is a centralized location that stores all available schemas.
Schemas define the structure of a data format. Schemas can be used for several purposes:
-
Validate the format of a Kafka message payload before further processing
-
Make data more compact for transmission
-
Extract information from the Kafka value to create MQTT messages
If you want to use serialized values that you extract from a Kafka record, you must first deserialize the values with an appropriate schema.
When you set the <use-schema-registry> setting to local or confluent in a topic mapping, you can specify the corresponding <schema-registries> in the configuration of your extension.
As your application changes over time, it can be useful to support multiple versions of a schema so that data encoded with older schemas is handled correctly. To help you ensure schema compatibility, the Confluent Schema Registry supports schema evolution.
Currently, the HiveMQ Enterprise Extension for Kafka supports the deserialization of Kafka values that use the Avro or JSON schema formats. The extension does not yet support deserialization of the Kafka key.
| Name | Default | Mandatory | Description |
|---|---|---|---|
|
- |
The list of one or more schema registries.
|
Local Schema Registry
The local schema registry resides on the same machine as the HiveMQ Enterprise Extension for Kafka.
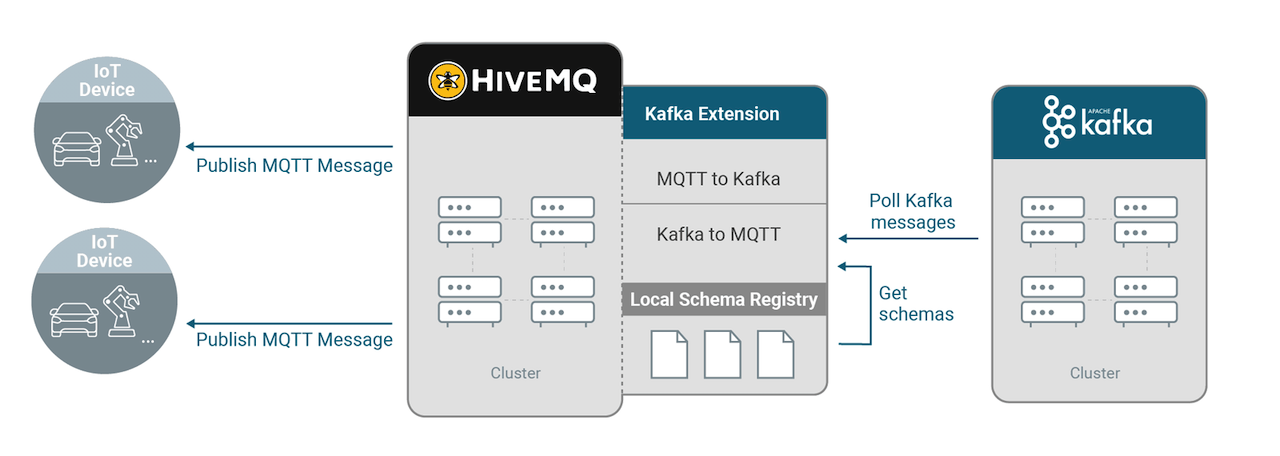
Your local schema registry can contain more than one schema file of the same type.
Each schema file that you want to use must be added to your local schema registry.
If you use a schema file, the HiveMQ extension checks each message that arrives against the selected schema and only processes valid messages.
| A Kafka topic can only have one schema file in the local schema registry. If a Kafka topic matches multiple entries in the local schema registry, the first schema that appears in the configuration file is used. |
| Name | Default | Mandatory | Description |
|---|---|---|---|
|
- |
The name of the local schema registry. |
|
|
- |
The list of one or more Avro schema entries.
|
|
|
- |
The list of one or more JSON Schema entries.
NOTE: Use |
To use the schema registry for all polled kafka-topics, use <kafka-topic-pattern>.*</kafka-topic-pattern>.
This pattern is a regular expression that matches every topic.
|
<kafka-configuration>
...
<schema-registries>
<local-schema-registry>
<name>local-register</name>
<avro-schema-entries>
<avro-schema-entry>
<serialization>binary</serialization>
<!-- The relative path where the avro file is searched is extensionhome/local-schema-registry/avro-schemafile.avsc -->
<avro-file>avro-schemafile.avsc</avro-file>
<kafka-topics>
<kafka-topic>the-first-kafka-topic</kafka-topic>
<kafka-topic>a-second-kafka-topic</kafka-topic>
</kafka-topics>
</avro-schema-entry>
</avro-schema-entries>
<json-schema-entries>
<json-schema-entry>
<!-- The relative path where the JSON file is searched is extensionhome/local-schema-registry/json-schemafile.json -->
<json-file>json-schemafile.json</json-file>
<kafka-topics>
<kafka-topic-pattern>a-regex-.*</kafka-topic-pattern>
</kafka-topics>
</json-schema-entry>
</json-schema-entries>
</local-schema-registry>
</schema-registries>
...
</kafka-configuration>Confluent Schema Registry
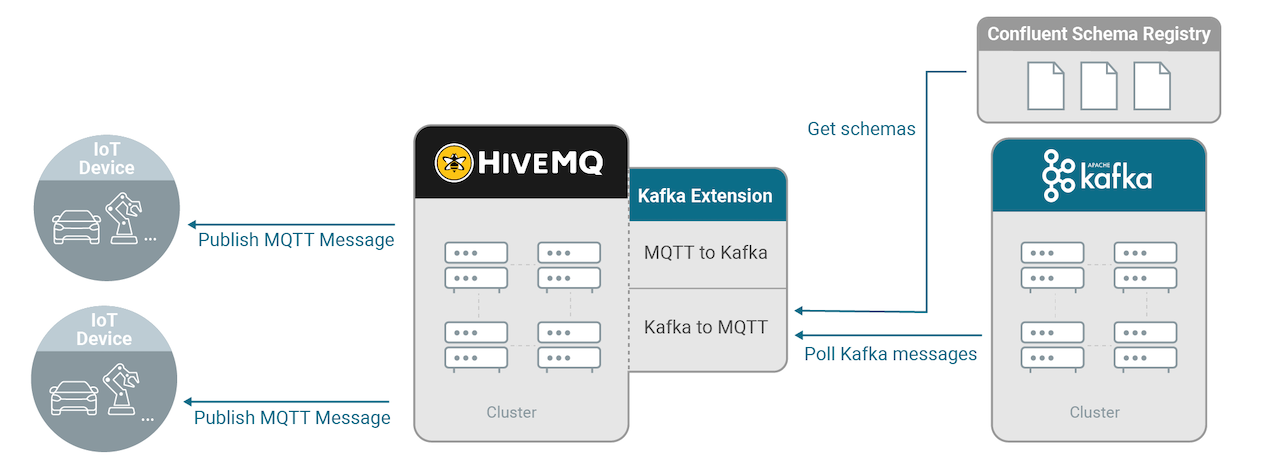
With the HiveMQ Enterprise Extension for Kafka, you can also use Confluent Schema Registry as a source for your schema files.
The Confluent Schema Registry is a distributed storage layer for schemas that uses Kafka as the underlying storage mechanism. Schema Registry automatically stores a versioned history of all your Avro schemas, checks compatibility, and retrieves the right schema for every incoming message to HiveMQ.
Through the ability to store and retrieve multiple versions of a schema, Schema Registry supports schema evolution that makes it easier to accommodate changes in data over time. For example, provide backward compatibility to avoid loss of data.
To prevent unnecessary calls to the Confluent Schema Registry, schema files that you have already used are cached in the extension.
| Name | Default | Mandatory | Description |
|---|---|---|---|
|
- |
The name of the Confluent schema registry. |
|
|
- |
The URL of the Confluent schema registry. To use a TLS connection, start the URL with |
|
|
- |
Defines options for the TLS connection.
|
|
|
- |
Defines HTTP authentication options to authenticate on the schema registry.
|
|
|
- |
The list of Kafka topics that this schema applies to.
NOTE: Use |
<kafka-configuration>
...
<schema-registries>
<confluent-schema-registry>
<name>confluent-sr</name>
<url>https://localhost:8081</url> <!-- If the URL starts with https:, TLS is enabled -->
<kafka-topics>
<kafka-topic>kafka-topic</kafka-topic>
</kafka-topics>
<!-- optional TLS configuration -->
<tls>
<!-- truststore, to trust the schema registry servers certificate -->
<truststore>
<path>/opt/hivemq/conf/kafka-trust.jks</path>
<password>truststorepassword</password>
</truststore>
<!-- keystore, when using SSL client authentication -->
<keystore>
<path>/opt/hivemq/conf/kafka-keystore.jks</path>
<password>keystorepassword</password>
<private-key-password>keypassword</private-key-password>
</keystore>
<!-- supported cipher suites -->
<cipher-suites>
<cipher-suite>TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA384</cipher-suite>
<cipher-suite>TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384</cipher-suite>
<cipher-suite>TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256</cipher-suite>
</cipher-suites>
<!-- supported TLS protocols -->
<protocols>
<protocol>TLSv1.2</protocol>
</protocols>
<!-- Specifies whether the client verifies the hostname of the server -->
<hostname-verification>true</hostname-verification>
</tls>
<!-- optional HTTP authentication configuration -->
<authentication>
<plain>
<username>srUser</username>
<password>srPassword</password>
</plain>
</authentication>
</confluent-schema-registry>
</schema-registries>
...
</kafka-configuration>Supported Formats
The HiveMQ Enterprise Extension for Kafka currently supports deserialization of the following formats with the local schema registry:
-
Avro
-
JSON (with JSON Schema Draft v4, v6, and v7 specifications for validation)
The HiveMQ Enterprise Extension for Kafka currently supports deserialization of the following formats with Confluent Schema Registry:
-
Avro
Authentication for Confluent Schema Registry
There are several ways to authenticate on a Confluent Schema Registry instance. For more information on how to configure authentication on the Schema Registry, see Schema Registry Security
-
HTTP authentication methods (configured in the
authenticationtag)-
Basic authentication: A simple username/password combination encoded in the HTTP headers of each request to the Schema Registry.
-
Bearer (token) authentication: Token-based authentication that encodes a token string into an HTTP header
-
-
TLS client authentication (configured in the
tls.keystoretag): The server requests a certificate from the client within the TLS handshake, which the client provides from its keystore.
| For the HTTP authentication methods you can use either basic or token authentication but not both at the same time. However, you can combine any HTTP authentication method (none, basic, bearer) with TLS client authentication. |
Kafka Constants
Kafka Constants are placeholders that represent various sections of information from a Kafka record.
At runtime, the HiveMQ Enterprise Extension for Kafka replaces the placeholders in the generated MQTT message with specific content from the Kafka record.
HiveMQ places the information that is read from the Kafka record directly into the placeholder without any transformation or deserialization.
In a Kafka to MQTT topic mapping, variables such as Kafka Constant placeholders are denoted with '${}'.
| Name | Description |
|---|---|
|
The value from the topic of the Kafka record. |
|
The value from the key of the Kafka record. |
|
The value from the value field of the Kafka record. |
<mqtt-topics>
<mqtt-topic>topic/test/topic-1</mqtt-topic>
<mqtt-topic>${KAFKA_TOPIC}</mqtt-topic>
<mqtt-topic>topic/test/${KAFKA_KEY}</mqtt-topic>
</mqtt-topics>
<mqtt-payload>${KAFKA_VALUE}</mqtt-payload>Supported Path Syntax
To extract values from fields of the deserialized Kafka value, the HiveMQ Enterprise Extension for Kafka uses a path syntax that is similar to the XPath syntax.
The path syntax is denoted by ${}.
-
//selects the root element -
/moves down in the tree -
nodenamespecifies the node that gets selected or moved to -
nodenames[x]selects the x-th element in the nodenames array.xis a 0-indexed value (unlike regular XPath syntax, which is 1-indexed).
The path must begin with the root element //.
|
The path must point to a value with the corresponding types.
For example, the path used for mqtt-payload must point to a field of the type Bytes.
|
<mqtt-topics>
<mqtt-topic>topic/example/topic-1/${//mqtt-information/topic}</mqtt-topic>
</mqtt-topics>
<mqtt-payload>${//mqtt-information/client[2]/payload}</mqtt-payload>Path Examples
This section provides examples of path semantic usage.
We use the Avro schema as a basis:
{
"type": "record",
"name": "userInfo",
"namespace": "my.example",
"fields": [
{
"name": "clientIDs",
"type": {
"type": "array",
"items": "string"
}
},
{
"name": "payload",
"type": "bytes"
},
{
"name": "publish_metadata",
"type": {
"type": "record",
"name": "publish_information",
"fields": [
{
"name": "retained",
"type": "boolean",
"default": "NONE"
},
{
"name": "payload_format_indicator",
"type": "string"
},
{
"name": "expiry",
"type": "long"
}
]
},
"default": {}
}
]
}This example shows how to extract client IDs and insert them into MQTT topics.
The format of the topics is test/client/<clientId>.
This format makes it possible to send one Kafka record to many MQTT topics.
To get the client IDs, we can use the path //clientIDs.
The configuration in the config.xml file is done as follows:
<mqtt-topics>
<mqtt-topic>test/client/${//clientIDs}</mqtt-topic>
</mqtt-topics>
The path must be placed within ${ and }
|
In the next example, we assume the field clientIDs contains the values ["clientId1", "clientId2", "clientId3"].
As a result, the MQTT publish is sent to the following three topics:
-
test/client/clientId1
-
test/client/clientId2
-
test/client/clientId3
To omit the first and last client ID and only send the MQTT Publish to the second client ID, we can add [1] at the end of the desired entry: //clientIDs[1].
(Since arrays begin at 0, we need to use [1] for the second entry)
<mqtt-topics>
<mqtt-topic>test/client/${//clientIDs[1]}</mqtt-topic>
</mqtt-topics>TLS
To connect to your Kafka clusters over a secure TCP connection, configure the TLS options in your <kafka-cluster> settings.
| Name | Default | Mandatory | Description |
|---|---|---|---|
|
|
If TLS is enabled, this setting can be set to |
|
|
All protocols the JVM enables |
The list of enabled protocols.
|
|
|
All cipher suites the JVM enables |
The list of enabled cipher suites.
|
|
|
- |
The key store to use.
|
|
|
- |
The trust store to use.
|
|
|
|
If hostname verification is enabled, this option can be set to |
<kafka-clusters>
<kafka-cluster>
<id>cluster01</id>
<bootstrap-servers>127.0.0.1:9092</bootstrap-servers>
<tls>
<enabled>true</enabled>
<!-- Truststore, to trust the Kafka server's certificate -->
<truststore>
<path>/opt/hivemq/conf/kafka-trust.jks</path>
<password>truststorepassword</password>
</truststore>
<!-- Keystore, when mutual TLS is used -->
<keystore>
<path>/opt/hivemq/conf/kafka-key.jks</path>
<password>keystorepassword</password>
<private-key-password>privatekeypassword</private-key-password>
</keystore>
<!-- Cipher suites supported by the client -->
<cipher-suites>
<cipher-suite>TLS_AES_128_GCM_SHA256</cipher-suite>
<cipher-suite>TLS_AES_256_GCM_SHA384</cipher-suite>
</cipher-suites>
<!-- Supported TLS protocols -->
<protocols>
<protocol>TLSv1.2</protocol>
</protocols>
<!-- If the client should verify the server's hostname -->
<hostname-verification>true</hostname-verification>
</tls>
</kafka-cluster>
</kafka-clusters>Authentication
Authentication against Kafka servers can be configured per Kafka cluster in the <kafka-cluster> settings.
The HiveMQ Enterprise Extension for Kafka supports the following authentication mechanisms:
| By default, the No Authentication option is enabled. |
<kafka-clusters>
<kafka-cluster>
...
<authentication>
<plain>
<username>kafka-user</username>
<password>kafka-password</password>
</plain>
</authentication>
</kafka-cluster>
</kafka-clusters>No Authentication
To disable authentication against the Kafka cluster, enter none as your authentication option.
<kafka-clusters>
<kafka-cluster>
...
<authentication>
<none/>
</authentication>
</kafka-cluster>
</kafka-clusters>Plain
Plain authentication uses only the username and password for authentication (not recommended).
<kafka-clusters>
<kafka-cluster>
...
<authentication>
<plain>
<username>kafka-user</username>
<password>kafka-password</password>
</plain>
</authentication>
</kafka-cluster>
</kafka-clusters>SCRAM SHA256
Authentication with Salted Challenge Response Authentication Mechanism (SCRAM) alleviates most of the security concerns that come with a plain username/password authentication.
<kafka-clusters>
<kafka-cluster>
...
<authentication>
<scram-sha256>
<username>kafka-user</username>
<password>kafka-user-secret</password>
</scram-sha256>
</authentication>
</kafka-cluster>
</kafka-clusters>SCRAM SHA512
Authentication with Salted Challenge Response Authentication Mechanism (SCRAM) alleviates most of the security concerns that come with a plain username/password authentication.
<kafka-clusters>
<kafka-cluster>
...
<authentication>
<scram-sha512>
<username>kafka-user</username>
<password>kafka-user-secret</password>
</scram-sha512>
</authentication>
</kafka-cluster>
</kafka-clusters>OAUTHBEARER
The extension authenticates against an OAuth 2.0-compliant Kafka deployment with the OAUTHBEARER SASL mechanism and the client credentials grant. The extension requests a bearer token from the configured token endpoint and presents it to the Kafka brokers.
This authentication mechanism always uses the SASL_SSL security protocol to connect to the Kafka brokers.
|
<kafka-clusters>
<kafka-cluster>
...
<authentication>
<oauthbearer>
<token-endpoint-url>https://auth.example.com/oauth2/token</token-endpoint-url>
<client-id>kafka-client</client-id>
<client-secret>${ENV:KAFKA_OAUTH_CLIENT_SECRET}</client-secret>
<scope>kafka</scope>
</oauthbearer>
</authentication>
</kafka-cluster>
</kafka-clusters>| Name | Default | Mandatory | Description |
|---|---|---|---|
|
- |
The OAuth 2.0 token endpoint URL from which the bearer token is requested. |
|
|
- |
The client identifier used to authenticate against the token endpoint. |
|
|
- |
The client secret used to authenticate against the token endpoint. |
|
|
- |
Optional OAuth scope to request for the token. |
The Kafka client requires you to list every token-endpoint-url in the org.apache.kafka.sasl.oauthbearer.allowed.urls Java system property.
To set the property, add it to your bin/run.sh file. For multiple URLs, use a comma-separated list. For example: JAVA_OPTS="$JAVA_OPTS -Dorg.apache.kafka.sasl.oauthbearer.allowed.urls=https://auth.example.com/oauth2/token".
If you leave the property unset, the extension manages it and keeps it in sync with Kafka configuration changes. If you set it manually (for example, via JAVA_OPTS), the value is fixed and does not change when the configuration reloads.
|
GSSAPI
The Generic Security Service Application Program Interface (GSSAPI) is used to allow authentication against Kerberos.
| If you use GSSAPI to authenticate the HiveMQ Enterprise Extension to your Kafka clusters via Kerberos, the Kafka client in the extension must have administrative rights. If admin rights are not enabled, the extension is not permitted to connect to Kafka. |
<kafka-clusters>
<kafka-cluster>
...
<authentication>
<gssapi>
<key-tab-file>/opt/hivemq/kafka-client.keytab</key-tab-file>
<kerberos-service-name>kafka</kerberos-service-name>
<principal>kafka/kafka1.hostname.com@EXAMPLE.COM</principal>
<store-key>true</store-key>
<use-key-tab>true</use-key-tab>
</gssapi>
</authentication>
</kafka-cluster>
</kafka-clusters>The use of a Kerberos ticket cache can be configured as follows:
<kafka-clusters>
<kafka-cluster>
...
<authentication>
<gssapi>
<use-ticket-cache>true</use-ticket-cache>
</gssapi>
</authentication>
</kafka-cluster>
</kafka-clusters>| Name | Default | Mandatory | Description |
|---|---|---|---|
|
- |
Enables the use of a keytab file. This option requires a configured |
|
|
- |
Absolute path to the keytab file. |
|
|
|
Name of the Kerberos service. |
|
|
- |
The name of the principal that is used. The principal can be a simple username or a service name. |
|
|
- |
Stores the keytab or the principal key in the private credentials of the subject. Allowed values are |
|
|
- |
Enables the use of a ticket cache. Allowed values are |
Microsoft Entra ID
Microsoft Entra ID enables secure passwordless connections with Azure Event Hubs for Kafka.
This feature enables several authentication methods, such as:
-
Environment (example: Service principal with secret)
-
Workload Identity (example: HiveMQ cluster running on Azure Kubernetes Service)
-
Managed Identity (example: HiveMQ cluster running on Virtual Machines in Azure)
Regardless of the method, permission to Azure Event Hubs must be granted on Azure. The way you obtain permission varies based on the service you use to run the HiveMQ cluster. For more information, see use passwordless connections with Azure Event Hubs for Kafka on your Azure hosting environment.
| To learn more about this feature and all authentication methods Azure supports, see DefaultAzureCredential in the official Azure documentation. |
This authentication mechanism always uses the SASL_SSL security protocol to connect to the Kafka brokers.
|
<kafka-clusters>
<kafka-cluster>
...
<authentication>
<microsoft-entra-id/>
</authentication>
</kafka-cluster>
</kafka-clusters>AWS Credential (IAM)
AWS Credential enables secure access control to Kafka services running on AWS using AWS Identity and Access Management (IAM).
This authentication mechanism enables access to Amazon Managed Streaming for Apache Kafka (MSK) using IAM access control.
| To learn more about this feature and all authentication methods AWS supports, see AWS Default Credentials Provider Chain. |
This authentication mechanism always uses the SASL_SSL security protocol to connect to the Kafka brokers.
|
<kafka-clusters>
<kafka-cluster>
...
<authentication>
<aws-credential/>
</authentication>
</kafka-cluster>
</kafka-clusters>| Name | Mandatory | Description |
|---|---|---|
|
Optional setting to configure authentication using an AWS Credential profile. When neither a
NOTE: The credentials file is expected to be in the default location. |
|
|
Optional setting to configure authentication using an AWS IAM Role. When neither a
|
|
|
Optional setting to configure the maximum number of retries the AWS MSK IAM credential provider performs. When unset, the default value |
Kafka Extension Customization
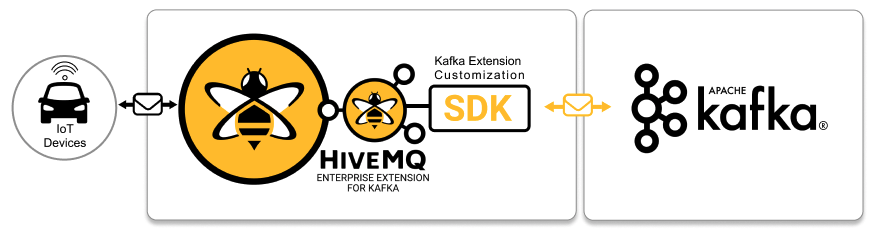
Our flexible API gives you the ability to customize the management of your Kafka topics and implement custom logic for MQTT-to-Kafka messaging. Use the API to programmatically specify sophisticated custom-handling of message transformations between HiveMQ and Kafka.
To enable the use of a custom transformer, you extend the config.xml file of your HiveMQ Enterprise Extension for Kafka.
MQTT-to-Kafka Extension Customization
| Setting | Mandatory | Description |
|---|---|---|
|
The unique identifier of the transformer. This string can only contain lowercase alphanumeric characters, dashes, and underscores. |
|
|
The identifier of the referenced Kafka cluster. |
|
|
The list of one or more MQTT topic filters.
|
|
|
The canonical class name of the transformer that is used. |
|
|
The Kafka acknowledgment mode. This mode specifies the way that the Kafka cluster must acknowledge incoming messages. Three Kafka acknowledgment modes are available:
For more information, see Kafka Producer acks. |
|
|
Optional setting to define the maximum size in bytes that a request to Kafka can contain. This value determines the largest MQTT message size that you can send to Kafka, and must be an integer greater than 0. The default value is 1 MB. This setting defines the NOTE: The maximum size the MQTT protocol allows in a single MQTT publish message is 256 MB. |
<mqtt-to-kafka-transformers>
<mqtt-to-kafka-transformer>
<id>my-transformer</id>
<cluster-id>cluster01</cluster-id>
<transformer>com.hivemq.extensions.kafka.transformer.MyCustomMqttToKafkaTransformer</transformer>
<mqtt-topic-filters>
<mqtt-topic-filter>transform/#</mqtt-topic-filter>
</mqtt-topic-filters>
</mqtt-to-kafka-transformer>
</mqtt-to-kafka-transformers>For detailed information, see HiveMQ Kafka Extension Customization SDK.
Kafka-to-MQTT Extension Customization
| Setting | Mandatory | Description |
|---|---|---|
|
The unique identifier of the transformer. This string can only contain lowercase alphanumeric characters, dashes, and underscores. |
|
|
The identifier of the referenced Kafka cluster. |
|
|
The list of one or more Kafka topics or Kafka topic patterns the transformer consumer subscribes to.
|
|
|
The canonical class name of the transformer that is used. |
<kafka-to-mqtt-transformers>
<kafka-to-mqtt-transformer>
<id>transformer01</id>
<cluster-id>cluster01</cluster-id>
<transformer>com.hivemq.extensions.kafka.transformer.MyCustomKafkaToMqttTransformer</transformer>
<kafka-topics>
<kafka-topic>first-kafka-topic</kafka-topic>
<kafka-topic>second-kafka-topic</kafka-topic>
<!-- arbitrary amount of kafka topics -->
<kafka-topic-pattern>first-pattern-.*</kafka-topic-pattern>
<kafka-topic-pattern>second-pattern-.*</kafka-topic-pattern>
<!-- arbitrary amount of kafka topic patterns -->
</kafka-topics>
</kafka-to-mqtt-transformer>
</kafka-to-mqtt-transformers>For detailed information, see HiveMQ Kafka Extension Customization SDK.
Kafka Dashboard in the HiveMQ Control Center
The Kafka Dashboard is available in HiveMQ Control Center v1 and v2. This page refers to v1, for v2 see HiveMQ Control Center (v2) - Kafka Dashboard.
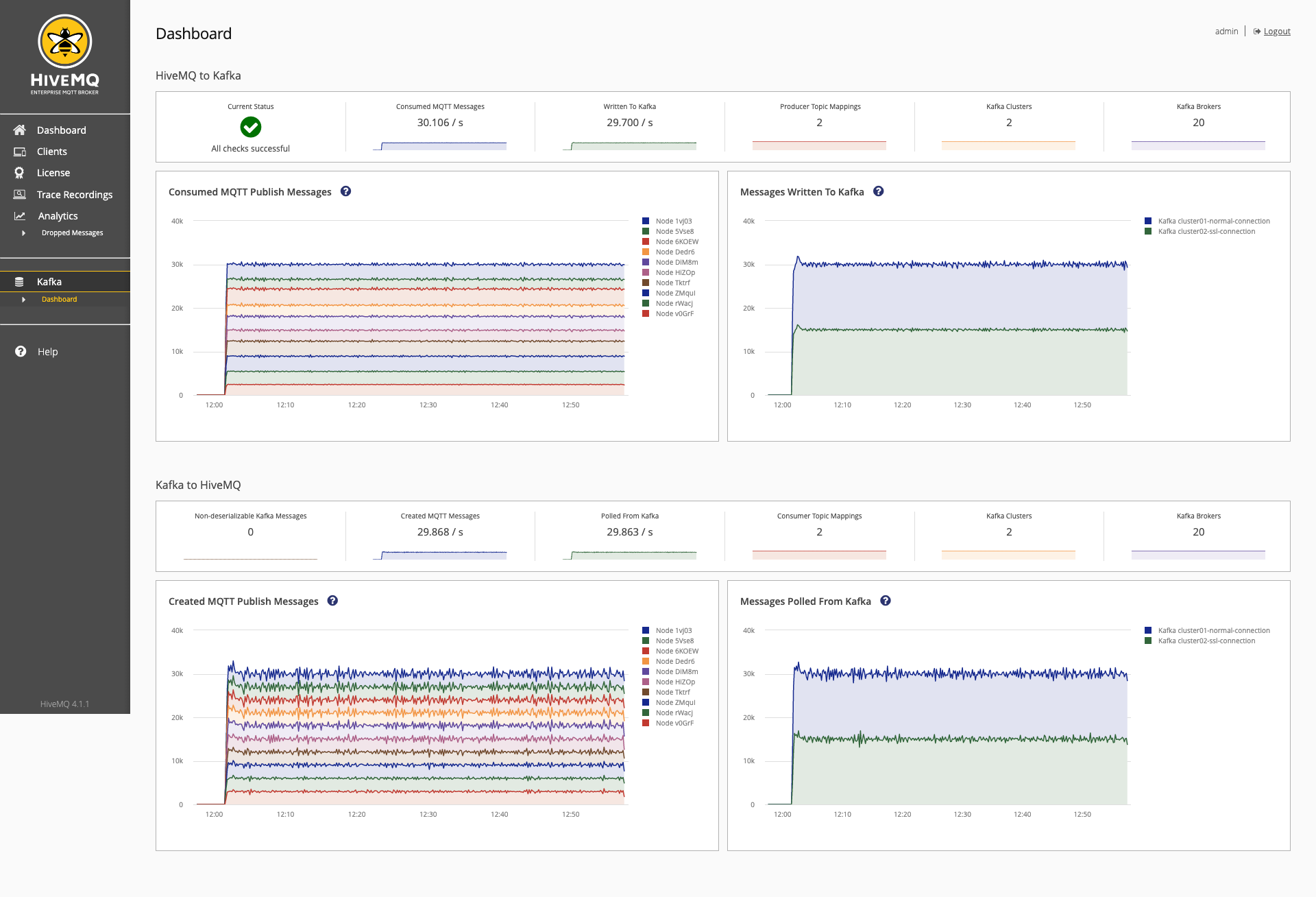
The HiveMQ Enterprise Extension for Kafka adds additional metrics to your HiveMQ Control Center. This information allows you to monitor the messages that the extension processes. Metrics are created for every action that can be measured.
The Dashboard for the HiveMQ Enterprise Extension for Kafka provides an overview bar and detailed graphs for both messaging directions: from MQTT to Kafka and from Kafka to MQTT.
MQTT-to-Kafka Section
The MQTT-to-Kafka section of the Kafka page provides information on MQTT messages that are sent to Kafka. The overview bar in the MQTT-to-Kafka section shows you the key metrics for all MQTT-to-Kafka mappings at a glance:

| Name | Value type | Description |
|---|---|---|
|
Status |
The current operational status of the extension. If manual intervention is required, errors or warnings display here. |
|
Messages per second |
The number of inbound MQTT Publish messages per second that the HiveMQ Enterprise Extension for Kafka processes. |
|
Messages per second |
The number of outbound messages that have already been written to Kafka. |
|
Absolute value |
The number of configured MQTT-to-Kafka topic mappings. |
|
Absolute value |
The number of configured Kafka clusters. |
|
Absolute value |
The number of available Kafka brokers that are visible to the extension. |
The detailed graphs provide additional insights into the messages the HiveMQ Enterprise Extension for Kafka processes.
The Consumed MQTT Publish Messages graph displays the Inbound MQTT Publish messages per second that are processed by the extension. Information is shown per HiveMQ cluster node.
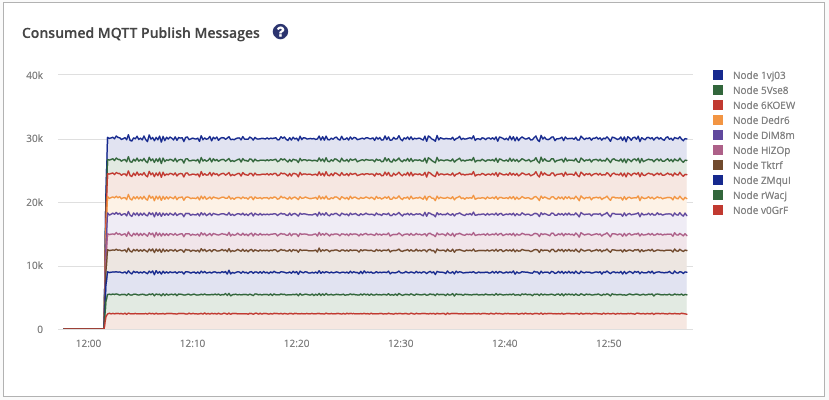
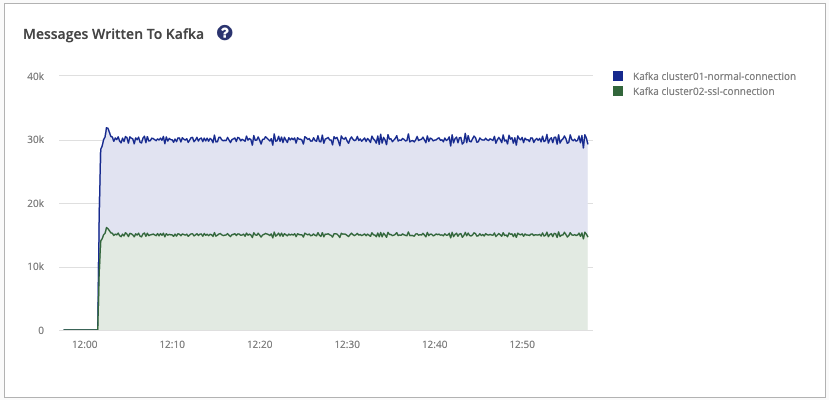
The Messages Written to Kafka graph displays the Outbound messages that are written to Kafka. These messages have been acknowledged by Kafka. Information is shown per Kafka cluster. It is expected that both graphs show an identical overall sum.
Kafka to MQTT Section
The Kafka-to-MQTT section of the Kafka page shows data on the information that is sent from Kafka to MQTT. The overview bar in the Kafka-to-MQTT section shows you the key metrics for all Kafka-to-MQTT mappings at a glance:

| Name | Value type | Description |
|---|---|---|
|
Absolute value |
The number of Kafka messages that could not be deserialized and used. |
|
Messages per second |
The number of inbound MQTT Publish messages per second that the HiveMQ Enterprise Extension produces. |
|
Messages per second |
The number of outbound messages that are polled from Kafka. |
|
Absolute value |
The number of configured Kafka-to-MQTT topic mappings. |
|
Absolute value |
The number of configured Kafka clusters. |
|
Absolute value |
The number of available Kafka brokers that are visible to the extension. |
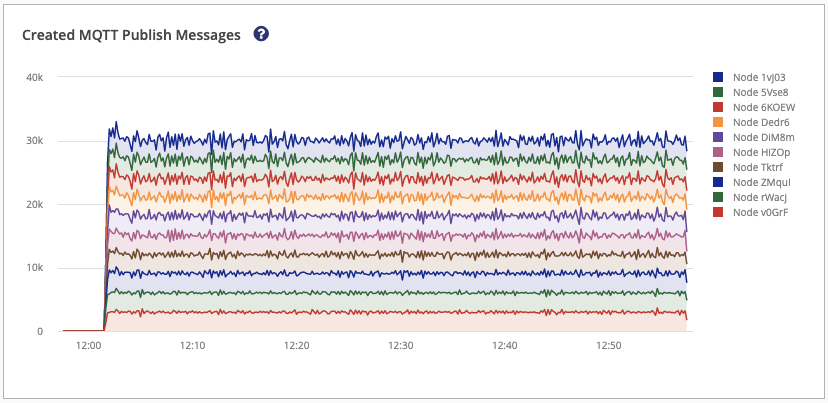
The Created MQTT Publish Messages graph displays the MQTT Publish messages per second that are created by the extension. Information is shown per HiveMQ cluster node.
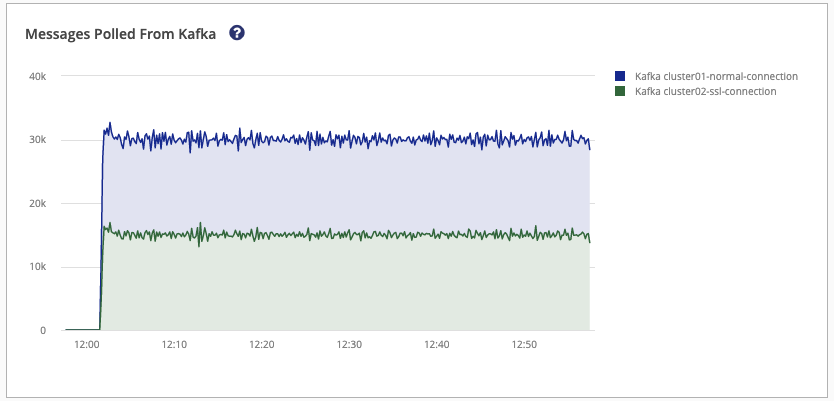
The Messages Polled From Kafka graph displays the inbound messages that are polled from Kafka. Information is shown per Kafka cluster. It is expected that the Created MQTT Publish Messages graph shows an identical or higher overall sum than the Messages Polled From Kafka graph. This discrepancy is due to scenarios in which multiple MQTT messages are created from a single Kafka record.
Kafka Extension Metrics
The HiveMQ Enterprise Extension Kafka provides several metrics that can be monitored to observe how the extension behaves over time.
| Name | Type | Description |
|---|---|---|
|
|
The total number of Kafka brokers to which the extension connects. |
|
|
The total number of Kafka producers. |
|
|
The total number of bytes read from Kafka. |
|
|
The total number of bytes written to Kafka. |
|
|
The total number of MQTT messages that MQTT to Kafka mappings and transformers consume. |
|
|
The total number of records the extension cannot produce to Kafka. |
|
|
The total number of records the extension ignored. |
|
|
The total number of records that were retried to be produced to Kafka. |
|
|
The total number of records the extension attempts to send to Kafka. |
|
|
The total number of records the extension successfully produced to Kafka. |
|
|
The total number of MQTT to Kafka mappings. |
|
|
The total number of MQTT to Kafka transformers. |
|
|
The number of records the extension successfully produces to Kafka cluster. |
|
|
The amount of time the extension requires to produce publishes to Kafka per topic mapping. |
|
|
The number of MQTT messages consumed per topic mapping. |
|
|
The number of records that the extension cannot produce to Kafka per topic mapping. |
|
|
The number of records the extension attempts to produce to Kafka more than once per topic mapping. |
|
|
The number of records the extension sends to Kafka per topic mapping. |
|
|
The number of records the extension successfully produces to Kafka per topic mapping. |
|
|
The total number of kafka-to-mqtt-mappings. |
|
|
The total number of kafka-to-mqtt-transformers. |
|
|
The number of connected Kafka brokers for kafka-to-mqtt messaging. |
|
|
The total number of times the rate limit of the PublishService is exceeded. |
|
|
The total number of Kafka records the Kafka to MQTT mappings and transformers receive from a Kafka cluster. |
|
|
The total number of Kafka records all Kafka to MQTT mappings and transformers in the extension receive. |
|
|
The total number of Kafka records that the extension cannot forward to HiveMQ of all Kafka to MQTT mappings and transformers. |
|
|
The total number of MQTT messages for which the extension did not create a Kafka record. |
|
|
The total number of Kafka records all Kafka to MQTT mappings and transformers retry. |
|
|
The total number of MQTT messages all Kafka to MQTT mappings and transformers publish from the received Kafka records. |
|
|
The number of schema retrieval retry attempts per schema registry. For example, when the schema registry is temporarily unavailable or authentication or authorization fails. |
|
|
The number of failed authentication attempts per schema registry. |
|
|
The number of successful authentication attempts per schema registry. |
|
|
The number of records the extension polls from Kafka per cluster. |
|
|
The amount of time the extension requires to produce publishes from Kafka records per topic mapping. |
|
|
The number of invalid records that are dropped per topic mapping. For example, schema not found, does not match schema, does not contain configured field mapped by path syntax. |
|
|
The number of records the extension polls from Kafka per topic mapping. |
|
|
The number of publishes the extension sends to MQTT per topic mapping. |
Kafka Extension Customization SDK Metrics
The following metrics are available when you implement an MQTT to Kafka or Kafka to MQTT transformer with the HiveMQ Kafka Extension Customization SDK:
| Name | Type | Description |
|---|---|---|
|
|
The amount of time the extension requires to transform an MQTT publish message to a Kafka topic per transformer. |
|
|
The number of MQTT messages consumed per transformer. |
|
|
The number of records that the extension cannot produce to Kafka per transformer. |
|
|
The number of MQTT messages for which the extension did not create a Kafka record per transformer. |
|
|
The number of records the extension attempts to produce to Kafka more than once per transformer. |
|
|
The number of records the extension attempts to send to Kafka per transformer. |
|
|
The number of records the extension successfully produces to Kafka per transformer. |
|
|
The amount of time the extension requires to produce publishes from Kafka records per transformer. |
|
|
The total number of unsuccessful transformation attempts, including multiple failures for the same Kafka record. |
|
|
The number of times the selected transformer returned an empty list of MQTT publishes. |
|
|
The number of Kafka records the selected transformer receives from a Kafka cluster. |
|
|
The number of times the selected transformer retries to transform Kafka records to MQTT publishes. |
|
|
The number of published MQTT messages the selected transformer created from Kafka Records. |
Support
If you need help with the HiveMQ Enterprise Extension for Kafka or have suggestions on how we can improve the extension, please contact us at contact@hivemq.com.