HiveMQ Enterprise Security Extension (ESE)
Concepts
Realms
Realms are abstract representations of external sources of authentication or authorization information. The ESE uses realms to authenticate connecting clients and authorize the future actions of the connecting clients. Specific types of realms correspond to the different types of authentication and authorization sources that are available. For example, the source behind an SQL realm is an SQL database.
Each type of realm has a specific configuration.
This example realm-configuration structure uses an sql-realm (1):
<enterprise-security-extension>
...
<realms>
<sql-realm> (1)
<name>realm-name</name>
<enabled>true</enabled>
<configuration>
<!-- enter specific configuration options, for example, database url and credentials -->
</configuration>
</sql-realm>
<!-- configure additional realms -->
</realms>
...
</enterprise-security-extension>In general, realms need to establish connections to external services. You must ensure that these external services are available for connection establishment when you start the extension.
This example realm-configuration structure uses a jwt-realm (1):
<jwt-realm>
<name>jwt-backend</name> <!-- mandatory -->
<enabled>true</enabled> <!-- mandatory -->
<configuration>
<jwks-endpoint>https://some.uri</jwks-endpoint> <!-- mandatory -->
<jwks-cache-duration>1800</jwks-cache-duration> <!-- optional, default is 1800 -->
<ssl-trust-store password="pass" type="jks">/file/path</ssl-trust-store> <!-- optional -->
<introspection-endpoint>https://another.uri</introspection-endpoint> <!-- optional -->
<simple-auth> <!-- optional -->
<user-name>clientName</user-name>
<password>client-secret</password>
</simple-auth>
</configuration>
</jwt-realm>Realms are configured in the <realms> tag of the ESE configuration file.
Each realm needs a unique name so it can be accurately referenced in your pipelines.
Since establishing a realm connection can be an expensive operation, all realms can be disabled for testing purposes.
Pipelines
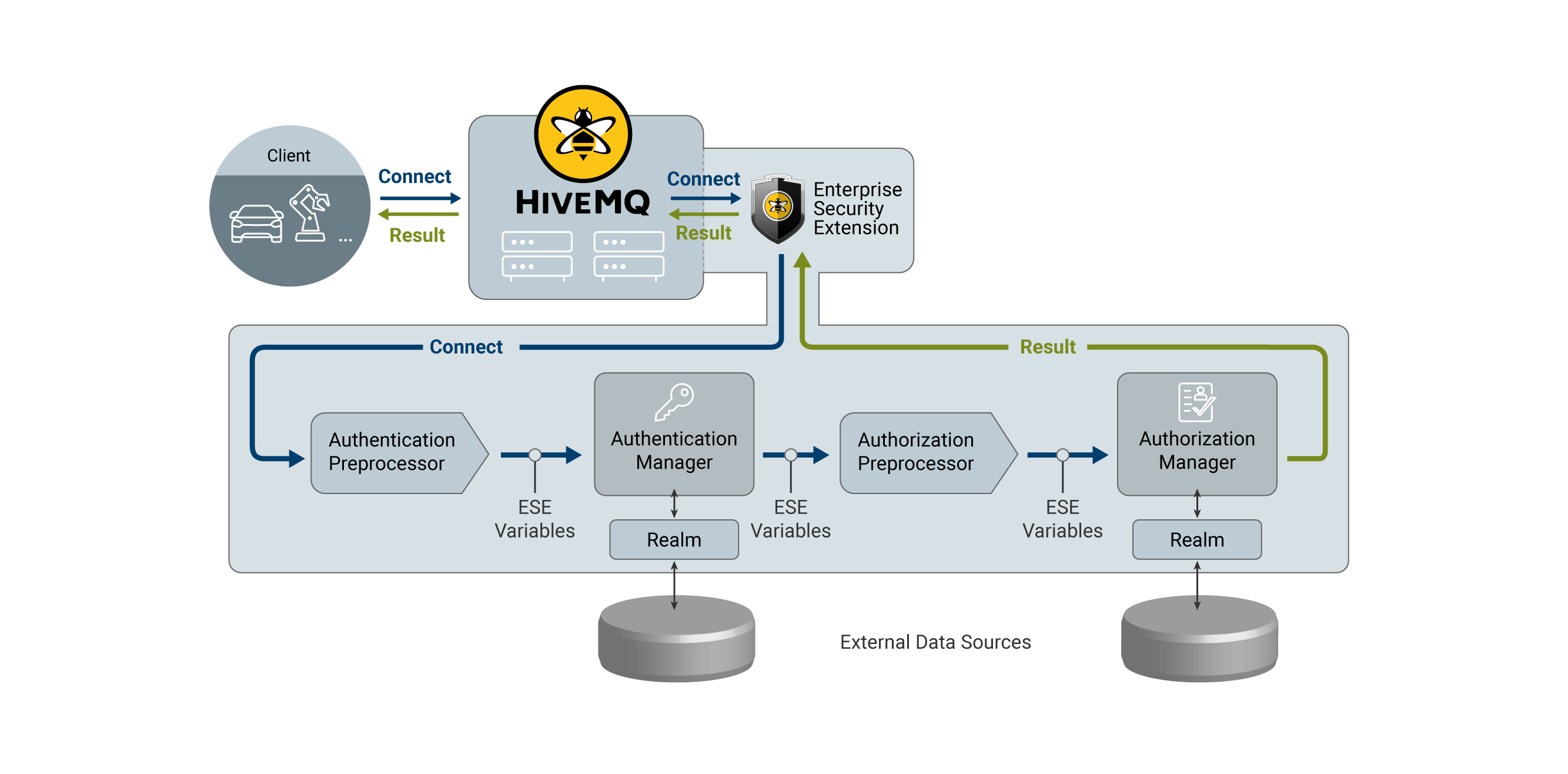
When a client tries to connect to HiveMQ, the client runs through a pipeline of the Enterprise Security Extension before the connection is accepted. This pipeline contains the individual steps that are required to authenticate and authorize the client. It is possible to configure multiple pipelines to authenticate or authorize different types of clients with different mechanisms.
Pipelines are highly configurable. However, a pipeline usually has four stages:
-
Authentication preprocessing
-
Authentication
-
Authorization preprocessing
-
Authorization

Authentication Preprocessing
Preprocessing is done with ESE variables.
When a client connects at the start of a pipeline, only the MQTT variables (mqtt-clientid,
mqtt-username, mqtt-password) are filled with the values the client provides in its CONNECT packet.
The purpose of authentication preprocessing is to fill the authentication variables that the next stage of the pipeline requires to actually authenticate the client.
The way variables are preprocessed and transformed is explained in the Preprocessors section.
Authentication preprocessing is optional. By default, the MQTT username and password are filled in as the authentication key and authentication secret.
Authentication
Authentication is performed by an authentication manager. For example, an SQL authentication manager that uses a database realm. The authentication manager uses the authentication variables to verify whether a client is authenticated to connect to HiveMQ. Additionally, the authentication manager can provide values for some authorization variables. For example, provide a role key that can be used for authorization.
Authorization Preprocessing
Preprocessing for authorization is similar to authentication preprocessing. The only difference is that authorization preprocessing fills or transforms the authorization variables.
Authorization
Authorization is performed by an authorization manager. For example, an SQL authorization manager that uses a database realm. The authorization manager uses authorization variables to query permissions for a client. These permissions define which operations the client is allowed to perform.
<enterprise-security-extension>
...
<pipelines>
<listener-pipeline listener="ALL">
<authentication-preprocessors>
...
</authentication-preprocessors>
<sql-authentication-manager>
...
</sql-authentication-manager>
<authorization-preprocessors>
...
</authorization-preprocessors>
<sql-authorization-manager>
...
</sql-authorization-manager>
</listener-pipeline>
<!-- configurations for additional pipelines -->
</pipelines>
</enterprise-security-extension>Listener Pipelines
When a client connects to HiveMQ, the Enterprise Security Extension selects the appropriate pipeline for the client.
It is possible to configure multiple pipelines that each map to different HiveMQ listeners. This enables you to authenticate and authorize backend applications and devices that connect over the internet differently.
<enterprise-security-extension>
...
<pipelines>
<listener-pipeline listener="listener-internet"> (1)
...
</listener-pipeline>
<listener-pipeline listener="listener-backend">
...
</listener-pipeline>
<listener-pipeline listener="ALL"> (2)
...
</listener-pipeline>
</pipelines>
</enterprise-security-extension>| 1 | The listener attribute takes the name of the listener that is defined in the HiveMQ config.xml. |
| 2 | ALL is a keyword for a special pipeline.
This pipeline is used if a client connects to a listener whose name does not match another pipeline. |
If a client connects to a listener whose name does not match any pipeline and no ALL pipeline is configured, the ESE rejects the connection attempt.

ESE Variables
The Enterprise Security Extension assigns a set of ESE variables to every connecting client. To give you maximum authentication and authorization flexibility, you can configure how the ESE variables are manipulated in the preprocessing stages of a pipeline.
There are two data types available for ESE variables:
-
String: ESE variables of this data type store a sequence of characters of arbitrary length or null
-
Byte: ESE variables of this data type store a sequence of bytes of arbitrary length or null
Additionally, ESE variables can be constant. Constant ESE variables contain read-only values that the ESE runtime system provides. Specific preprocessors can only use specific types of ESE variables.
Some ESE variables have predefined meanings, others can be used as general purpose variables. ESE variables are grouped into four categories:
MQTT Variables
MQTT variables are initialized by the ESE runtime system. The value of an MQTT variable is derived directly from the MQTT CONNECT packet of the connecting client.
| Name | Data type | Description |
|---|---|---|
|
Constant string |
Set to the client ID of the connecting client. |
|
Constant string |
Set to the user name field of the connecting client. |
|
Constant byte |
Set to the password field of the connecting client. |
General Purpose Variables
General purpose variables do not have a predefined meaning. These variables can be used during pipeline processing as desired. At the start of a pipeline, the initial state of a general purpose variable is always null.
| Name | Data type |
|---|---|
|
Byte |
|
String |
Authentication Variables
Authentication variables are used by the authentication managers to verify the identity of a connecting client. These variables are usually manipulated in the authentication-preprocessing step of a pipeline.
| Name | Data type | Description |
|---|---|---|
|
String |
The authentication-key is generally used by the authentication manager to identify the connecting client. |
|
Byte |
The authentication-byte-secret is generally used by the authentication manager to ensure the claims of the connecting client. |
Authorization Variables
Authorization variables are used by the authorization managers to specify access rights to MQTT topics. Based on the state of the authorization variables, the authorization manager assigns permissions to a connecting client. Authorization variables are usually manipulated in the authorization-preprocessing step of a pipeline.
| Name | Data type | Description |
|---|---|---|
|
String |
The authorization-key is generally used by the authorization manager to assign client-specific permissions. |
|
String |
The authorization-role-key is generally used by the authentication manager to assign permissions that are inherent to a conceptional group of clients. |
Permission Placeholders
Permission placeholders facilitate the creation of permissions for groups of clients that require similar, but client-specific permissions. The use of permission placeholders can eliminate the need to create individual permissions for each client.
The placeholders can be used inside the topic filter and shared group of a permission. All ESE variables of the string data type can be used as placeholders. At the end of the authorization step, the placeholders are dynamically replaced with the values of the referenced ESE variables.
To create a permission with a placeholder, insert the name of the ESE variable framed with ${ and } at the desired position in the permission.
Example for permission placeholders:
-
The authorization manager grants subscription to the topic filter
topic/${mqtt-clientid}/${string-1}/subtopic. -
If the value of mqtt-clientid is
my-special-clientand string-1 islast, then the connecting client is only allowed to subscribe with the topic filtertopic/my-special-client/last/subtopic.
| Only variables of the string data type can be substituted. Byte variables can not be replaced. |
Preprocessors
In a pipeline, you can add preprocessing steps before authentication and before authorization. The preprocessing is done through the configuration of one or more preprocessors. Preprocessors are lightweight pipeline steps that work with the current state of the ESE variables and have no external dependencies.
Plain Preprocessor
The plain preprocessor offers a way to transfer the state of ESE variables. It contains a list of one or more transformations. During runtime, the transformations are processed in the order in which they appear in the configuration file.
<plain-preprocessor>
<transformations>
<transformation>...</transformation>
<transformation>...</transformation>
<transformation>...</transformation>
<!-- add more transformations-->
</transformations>
</plain-preprocessor>A transformation copies values from one ESE variable to another ESE variable.
These variables are annotated as from and to variables.
After the transformation process, the value in the from variable is stored in the to variable as well as in the
from variable.
Constant ESE variables are not permitted in a to variable.
If the data type of the from and to variables differ, an encoding must be specified.
<transformation encoding="UTF8">
<from>byte-1</from>
<to>string-1</to>
</transformation>| Parameter | Type | Description |
|---|---|---|
|
Defines how the ESE variable referenced in the |
|
|
String |
References the ESE variable in which the incoming data of the transformation is stored. |
|
String |
References the ESE variable in which the outgoing data of the transformation is stored. |
| Encoding | Description |
|---|---|
|
Uses the UTF-8 encoding as specified in RFC 3629. |
|
Uses the Base64 encoding as specified in RFC 4648. Some transformations produce or require padding of up to two |
Regex Preprocessor
The regex preprocessor allows you to pull substrings from a string ESE variable with the help of regular expressions. The preprocessor takes the value of the selected string variable, matches a pattern, and writes the resulting matches back into the string variable.
The regex preprocessor is useful when just a part of an ESE variable must be used for authentication or authorization purposes. Here are some examples:
-
All client passwords start with the phrase password followed by the real secret.
-
A part of the client ID needs to be inserted into the topic permissions to specify the client.
-
Only the first three characters of the user name are relevant.
The regex preprocessor contains a regular expression pattern, an optional group number, and a list of ESE variables to which the preprocessor is applied.
<regex-preprocessor>
<pattern>mqtt-client=((.{3})-(.{3}))</pattern>
<group>1</group>
<variable>authentication-key</variable>
</regex-preprocessor>| Parameter | Type | Description |
|---|---|---|
|
String |
The regular expression that is used |
|
Positive integer or |
The group in the regular expression that is extracted. Groups are framed with parenthesis |
|
String |
References the ESE variable that is processed. This tag can be present multiple times. |
Regular Expression Syntax
The regex preprocessor expands the regular expressions syntax that the HiveMQ Control Center uses to include grouping logic.
To add a group to a pattern, include a pair of matching parenthesis ().
Groups are ordered by their opening parenthesis ( from left to right.
Regardless of the parenthesis, the 0 group is always present and contains the whole matched pattern.
For example, a variable that contains the string "SOMETHINGmqtt-client=abc-defSOMETHING" is processed with the pattern
mqtt-client=((.{3})-(.{3})) that contains four groups.
Based on the matched group, the value of the string variable after preprocessing is as follows:
| Group Number | New Value |
|---|---|
|
|
|
|
|
|
|
|
Concatenation Preprocessor
The Concatenation Preprocessor allows you to join the values of multiple string ESE variables and place the concatenated result into a single ESE variable.
The Concatenation Preprocessor contains one or more input string ESE variables and a single output string ESE variable. If desired, you can define a prefix and postfix to enclose the values of every input string ESE variable that is given.
<concatenation-preprocessor prefix="{{" postfix="}}">
<from>string-1</from>
<from>string-2</from>
<to>string-3</to>
</concatenation-preprocessor>| Parameter | Type | Description |
|---|---|---|
|
String (XML attribute) |
Specifies the characters that are used before a value to separate multiple values in a field (optional). Default: |
|
String (XML attribute) |
Specifies the characters that are used after a value to separate multiple values in a field (optional). Default: |
|
String |
References the string ESE variables that are concatenated. This tag can be present multiple times. |
|
String |
References the string ESE variable where the string that is the result of the concatenation is placed. |
Concatenation Preprocessor Example
If you use the Concatenation Preprocessor example configuration, you can expect the following behavior:
This example shows how the values of the string-1 and string-2 ESE variables are concatenated.
The result of the concatenation is placed in the string-3 ESE variable.
The string-1 ESE variable contains the value "Lorem" and the string-2 ESE variable contains the value "Ipsum".
After processing, the string-3 ESE variable contains the value "{{Lorem}}{{Ipsum}}".
Split Preprocessor
The Split Preprocessor allows you to divide the value of a string ESE variables into multiple tokens and place the resulting tokens into one or more ESE variables.
The Split Preprocessor contains one input string ESE variable and one or more output string ESE variables. You can also define a prefix and a postfix, that enclose the individual substrings in the input string ESE variable.
<split-preprocessor prefix="{{" postfix="}}">
<from>string-1</from>
<to>string-2</to>
<to>string-3</to>
</split-preprocessor>| Parameter | Type | Description |
|---|---|---|
|
String (XML attribute) |
The characters used before an extracted value to separate multiple values in a field. Default: |
|
String (XML attribute) |
The characters used after an extracted value to separate multiple values in a field. Default: |
|
String |
References the string ESE variable that is divided into separate tokens. |
|
String |
References the string ESE variables where the tokens are placed. This tag can be present multiple times. |
| If more tokens are present than destination variables, the surplus tokens are not placed in a string ESE variable. |
Split Preprocessor Example Usage
When you use the Split Preprocessor example configuration, you can expect the following behavior:
This example shows how the value of the string-1 ESE variable is split into 2 strings (tokens) that
are placed in the string-2 and string-3 ESE variables.
The string-1 ESE variable contains the value "{{Lorem}}{{Ipsum}}".
After processing, the string-2 ESE variable contains the value "Lorem" and
the string-3 ESE variable contains the value "Ipsum".
This example shows how the value of the string-1 ESE variable is divided into tokens when only 2 destination
ESE variables are given. As a result, the third token is ignored.
The string-1 ESE variable contains the value "{{Lorem}}{{Ipsum}}{{Dolor}}".
After processing, the string-2 ESE variable contains the value "Lorem" and
the string-3 ESE variable contains the value "Ipsum".
The "Dolor" value is not placed in any ESE variable.
X.509 Preprocessor
The X.509 preprocessor makes it possible to use information that is provided in the X.509 certificate of a connecting MQTT client for authentication and authorization of the client in HiveMQ.
You can use the X.509 preprocessor to extract values from specific fields in the X.509 certificate of the client and copy the values to an ESE variable.
If desired, add one or more regex preprocessors to transform the information that you extract automatically.
The HiveMQ X.509 preprocessor can extract values from the following X.509 certificate fields:
-
Issuer Common Name: The name of the entity that provides the X.509 certificate. This field is limited to one entry and a maximum of 64 characters.
-
Subject Common Name: The name of the entity that the X.509 certificate protects. This field is limited to one entry and a maximum of 64 characters.
-
Common Names from the Issuer Alternative Names extension: Additional names for the entity that provides the certificate. This field can contain multiple entries. The object identifier (OID) for this field is 2.5.29.18.
-
Common Names from the Subject Alternative Names extension: Additional names for the subject of the certificate. This field can contain multiple entries. The OID for this field is 2.5.29.17.
X.509 Preprocessor Configuration
The X.509 preprocessor contains a list of X.509 extractions and a configurable prefix/postfix (for fields that allow multiple entries).
<enterprise-security-extension>
<pipelines>
<listener-pipeline listener="listener">
<authentication-preprocessors>
<x509-preprocessor prefix="{{" postfix="}}">
<x509-extractions>
<x509-extraction>
<x509-field>subject-common-name</x509-field>
<ese-variable>authentication-key</ese-variable>
</x509-extraction>
</x509-extractions>
</x509-preprocessor>
</authentication-preprocessors>
</listener-pipeline>
</pipelines>
</enterprise-security-extension>| Parameter | Type | Description |
|---|---|---|
|
String (XML attribute) |
The characters used before an extracted value to separate multiple values in a field. Default: |
|
String (XML attribute) |
The characters used after an extracted value to separate multiple values in a field. Default: |
|
x509-extraction |
A list of x509-extractions that specify how the values that are stored in an X.509 certificate are transformed into ESE variables. |
| Parameter | Type | Description |
|---|---|---|
|
XML enum |
The field in the X.509 certificate that is extracted into the ESE variable.
Possible values are: |
|
XML enum |
The ESE variable that stores the extracted information. This ESE variable must be a non-constant string variable. |
In an X.509 certificate, some fields can contain more than one entry. If a field contains multiple entries, the entries of the field are wrapped in the configured prefix and postfix and concatenated before they are written into the ESE variable.
For example, the MQTT client of a car-pool vehicle provides a certificate that contains the following two subject-alternative common names:
-
id-1234567(the identification number of the car) -
car-pool-south-east(the car-pool group to which the car belongs)
After extraction into an ESE variable with the default prefix/postfix, the ESE variable contains the following concatenated string:
{{id-1234567}}{{car-pool-south-east}}
In this example, a regex preprocessor with the pattern {{.}}{{(.)}} and group 1 is applied.
The regex preprocessor creates an ESE variable that contains the following string:
car-pool-south-east
Next, a preconfigured authorization manager uses the resulting ESE variable to assign role-based permissions to the MQTT client of the car-pool vehicle.
JWT Preprocessor
The JWT preprocessor makes it possible to extract information that is provided in the JSON Web Token (JWT) of a connecting MQTT client for authentication of the client in HiveMQ.
The HiveMQ Enterprise Security Extension retrieves information from the payload of the JWT. The JWT payload contains Base64URL encoded information about the bearer of the token. Each statement in the JWT payload is called a claim.
You can use the JWT preprocessor to extract values from specific claims in the JWT that the MQTT client presents and copy the value to an ESE variable.
If desired, add one or more regex preprocessors to transform the information that you extract automatically.
JWT Preprocessor Configuration
The JWT preprocessor contains a list of extractions and a configurable prefix/postfix (for fields that allow multiple entries).
<jwt-preprocessor prefix="{{" postfix="}}">
<source>authentication-byte-secret</source>
<jwt-extractions>
<jwt-extraction>
<jwt-claim>azp</jwt-claim>
<ese-variable>string-1</ese-variable>
</jwt-extraction>
</jwt-extractions>
</jwt-preprocessor>| Parameter | Type | Description |
|---|---|---|
|
String (XML attribute) |
The characters used before an extracted value to separate multiple values in a field. Default: |
|
String (XML attribute) |
The characters used after an extracted value to separate multiple values in a field. Default: |
|
ESE Variable |
The byte variable that contains the JWT. |
|
jwt-extraction |
A list of jwt-extractions that specify how the values that are stored in a JWT are transformed into ESE variables. |
| Parameter | Type | Description |
|---|---|---|
|
String |
The field in the JWT that is extracted into the ESE variable.
For example, reserved-claim values such as |
|
The ESE variable that stores the extracted information. This ESE variable must not be constant. |
In a JWT, some claims can contain more than one entry. If a claim contains multiple entries, the entries of the field are wrapped in the configured prefix and postfix and concatenated before they are written into the ESE variable.
Logging Preprocessor
The logging preprocessor offers a way to debug the state of ESE variables. At the pipeline stage where the preprocessor is placed, the content of the variables is output to a logger. The loggers are placed in the pipeline in same the order in which they appear in the configuration file.
| Logging preprocessors impact performance. Only use logging preprocessors for debugging purposes. |
<logging-preprocessor>
<message>The content of the string-1 ESE-Variable: ${string-1}</message>
<level>debug</level>
<name>com.example.logger</name>
</logging-preprocessor>| Parameter | Type | Default | Description |
|---|---|---|---|
|
String |
Defines the message that is output to the logger. Use the following syntax to input the ESE variables: ${ESE_VARRIABLE_NAME}. |
|
|
debug |
The logging level of the message. |
|
|
String |
The name of the logger. |
|
|
Base64 |
The encoding of byte ESE variables. |
| Level | Description |
|---|---|
|
Trace Logging Level |
|
Debug Logging Level |
|
Info Logging Level |
|
Warn Logging Level |
|
Error Logging Level |
Set the Log Level
By default, the root level that is set in the HiveMQ logback.xml is used. If you wish to set the log level for a specific logging preprocessor, you can define the level in the HiveMQ logback.xml.
<configuration scan="true" scanPeriod="60 seconds">
...
<logger name="<LOGGING_PREPROCESSOR_NAME>" level="debug"/>
...
</configuration><configuration scan="true" scanPeriod="60 seconds">
...
<logger name="<LOGGING_PREPROCESSOR_NAME>" level="info"/>
...
</configuration><configuration scan="true" scanPeriod="60 seconds">
...
<logger name="<LOGGING_PREPROCESSOR_NAME>" level="trace"/>
...
</configuration>Cryptographic Operations
Usage of Cryptography
The ESE uses cryptography to compare securely-stored secrets with the secrets that the MQTT clients provide for authentication. To make the comparison, the ESE currently employs four different password hashing schemata.
All schemata can be scaled in computational difficulty and all schemata allow for the use of an optional salt. Difficulty scaling is done with a difficulty parameter (if the one-way function that is used supports this parameter) or by using the output of the function as input in additional rounds of hashing. The Salt is used in the way that is specified by the one-way function or it is prepended once before the first round of hashing is done.
The ESE expects all byte strings such as hashed passwords to be encoded with the Base64 encoding scheme.
Once the cryptographic processing of the client-provided secret is done, the ESE compares the result with the configured trust for bit equality.
MD5
The ESE can use the MD5 message digest.
-
The salt is prepended to the secret before the first round of hashing.
-
The difficulty is scaled by using the output of MD5 again as input for iteration-times rounds.
-
The resulting hash has a length of 16 bytes or 24 characters in Base64 encoding.
| MD5 is proven to be insufficiently strong for modern security standards and is only made available for testing and legacy purposes. |
SHA512
The ESE can use the Secure Hashing Algorithm 2 with an output bit-length of 512 (SHA512).
-
The salt is prepended to the secret before the first round of hashing.
-
The difficulty is scaled by using the output of SHA512 again as input for iteration-times rounds.
-
The resulting hash has a length of 64 bytes or 87 characters in Base64 encoding.
BCRYPT
The ESE can use the Blowfish cipher-based password hashing scheme bcrypt.
-
The salt is hashed with MD5 to resize it before use. Because bcrypt requires the use of a salt, an empty string is hashed and used if no salt is configured.
-
The secret is hashed with SHA512 to resize it before use.
-
The iteration parameter is directly used as the difficulty parameter of bcrypt. Only values between 4 and including 31 are allowed.
-
The resulting hash has a length of 24 bytes or 32 characters in Base64 encoding.
PKCS5S2
The ESE can use the PKCS 5 V2.0 Scheme 2 as described in RFC 2898.
-
The underlying one-way function is SHA512.
-
The difficulty and the salt are directly passed on to the scheme.
-
The resulting hash has a length of 32 bytes or 44 characters in Base64 encoding.
PLAIN
The PLAIN schema (available in ESE version 1.1) is not a cryptographic operation. This schema simply prompts the ESE to do a plain-text secret comparison (without any transformation of the provided secret beforehand).
-
No one-way function is used.
-
Any difficulty parameter or salt is ignored.
-
The length of the resulting byte string or Base64 encoding is highly dependent on the secret that is used.
| Only use the PLAIN schema if you have a specific use case that requires this schema. Because the performance of the PLAIN schema is very different from real hash functions, the schema is unsuitable even for testing purposes. |
Authentication and Authorization
The key tasks of the Enterprise Security Extension are authentication and authorization of MQTT clients. For a detailed explanation of these concepts in the context of HiveMQ, see Authorization Options for Your HiveMQ Extension.
Authentication Managers
Authentication verifies whether a person, device, or application is who they say they are.
In the ESE, authentication is done by authentication managers. An authentication manager is defined in a pipeline and handles the authentication processes of connecting MQTT clients by using the content of the authentication variables.
Authorization Managers
Authorization defines which actions a specific person, device, or application is allowed to perform. Authorization can be split up into the concepts of roles and permissions.
A permission contains a set of actions. Users who are granted a specific permission are allowed to do the actions that are defined in the permission.
Permissions can also be assigned to a role. This role can then be assigned to a set of users. Users who have a certain role receive all of the permissions that are assigned to the role.
In the ESE, authorization is done by authorization managers. An authorization manager is defined in a pipeline and handles the authorization processes of connecting MQTT clients by using the content of the authorization variables.
| We highly recommend the use of roles to assign permissions rather than the assignment of user-specific permissions. The use of roles to manage permissions creates a clear authority structure on your system and can improve overall performance of the ESE. |
Allow-all Authentication and Authorization Managers
The ESE provides two special authentication and authorization managers to facilitate testing. These managers allow all clients to connect to HiveMQ without checking the credentials or permissions of the connecting client. The allow-all managers are especially useful when you want to test your authentication or authorization workflow individually. For example, to test whether all clients can connect to your SQL authentication manager, you can use the allow-all authorization manager to exclude failed authentications that authorization causes.
The allow-all managers can be used for testing in the HiveMQ listener pipelines. Based on your use case, you can use the allow-managers separately or in unison.
Allow All Authentication Manager Configuration
<pipelines>
<pipeline>
<allow-all-authentication-manager/>
<!-- add authorization preprocessors if necessary -->
<!-- add an authorization manager -->
</pipeline>
</pipelines>Allow All Authorization Manager Configuration
<pipelines>
<pipeline>
<!-- add authentication preprocessors if necessary -->
<!-- add an authentication manager -->
<allow-all-authorization-manager/>
</pipeline>
</pipelines>| The allow-all authentication and authorization managers are intended for testing purposes only. We do not recommend the use of these managers in a production environment. |
SQL Databases
The HiveMQ Enterprise Security Extension supports different SQL databases as external sources of authentication and authorization data.
In the ESE configuration file, you can use the abstract representation of SQL realms to define the connection to one or more databases.
SQL realms can be referenced in SQL authentication managers and/or
SQL authorization managers.
To enable the ESE to work with the stored information, the databases must adhere to the
SQL structure that is described below.
In the ESE, SQL realms and the associated managers support access control for the HiveMQ Control Center.
To use the access-control feature for your control center, you need to set up additional SQL tables.
The ESE supports the following SQL databases:
See the full list of supported database versions.
SQL Realm
To connect the HiveMQ Enterprise Security Extension to an SQL database, simply configure an SQL realm in the <realms>
section of your ESE configuration.
The SQL realm must contain the database connection information and have a unique name that the authentication and authorization managers can reference.
<enterprise-security-extension>
...
<realms>
<sql-realm>
<name>sql-realm-name</name>
<enabled>true</enabled>
<configuration>
<db-type>POSTGRES</db-type>
<db-name>hivemq</db-name>
<db-host>hostname</db-host>
<db-port>5432</db-port>
<db-username>hivemq</db-username>
<db-password>password</db-password>
</configuration>
</sql-realm>
</realms>
...
</enterprise-security-extension>| Parameter | Type | Mandatory | Description |
|---|---|---|---|
|
Specifies the database technology |
||
|
String |
Specifies the database within the DBMS |
|
|
String |
Specifies the remote address of the database |
|
|
Integer |
Specifies the remote port of the database |
|
|
String |
Specifies the username that the ESE uses to connect to the database |
|
|
String |
Specifies the password that the ESE uses to authenticate itself |
Caching
The querying of SQL databases incurs a significant overhead in execution time. To remedy this, ESE caches information gained from connected databases.
The amount of time each type of data is cached before a time-based eviction can occur is predefined:
-
Authentication data, specifically the user name and the corresponding user information are cached for one minute.
-
User permissions are cached for five minutes.
-
Role permissions are cached for one full day.
| As cache size is limited, evictions can occur before the caching time expires. |
| Authentication failures caused within the database, e.g. due to the user not existing, are also cached for one minute. |
These caching rules also apply to the corresponding control-center data.
Supported Database Technologies
Since the ESE supports various types of SQL databases, you must specify the type of database for each realm. Use the following predefined strings to specify the SQL database type:
| SQL Type | Database Technology |
|---|---|
|
Use this type to connect to a PostgreSQL database |
|
Use this type to connect to a MySQL or MariaDB database |
|
Use this type to connect to an MSSQL database |
|
Use this type to connect to an Amazon Aurora database, using the PostgreSQL API. |
|
Use this type to connect to an Amazon Aurora database, using the MySQL API. |
|
Use this type to connect to an Azure SQL database |
| Amazon Aurora offers the possibility to use a PostgreSQL or a MySQL API. You can specify the preferred type at database creation. If you do not know which database type you are using, you can check the RDS overview in the AWS management console. |
SQL Authentication Manager
To use an SQL database as an external source for authentication, configure an SQL authentication manager in the desired pipeline and reference the corresponding SQL realm name in the authentication manager.
The ESE uses the authentication variables to look up authentication information in the database.
By default, the authentication variables are filled with the MQTT variables mqtt-username and mqtt-password.
If you want to adapt the values of the authentication variables, you can use a preprocessor before the SQL authentication manager.
If you configure preprocessors before the authentication manager, make sure that the authentication variables are set. The mqtt-username and mqtt-password are not automatically used in this case.
|
To ensure that the ESE can find the authentication information in the database, the layout of the database must be in accordance with the database table 'users' of the SQL database structure.
If the authentication manager gets also authorization information from the database, it sets the
authorization variables authorization-key and authorization-role-key too.
<enterprise-security-extension>
<!-- add realms configuration -->
<pipelines>
<pipeline>
<!-- add authentication preprocessors if necessary -->
<sql-authentication-manager>
<realm>sql-realm-name</realm>
</sql-authentication-manager>
<!-- add authorization preprocessors if necessary -->
<!-- add an authorization manager -->
</pipeline>
</pipelines>
</enterprise-security-extension>| Parameter | Type | Mandatory | Description |
|---|---|---|---|
|
String |
References the SQL realm from which the authentication data is drawn. |
SQL Authorization Manager
To use an SQL database as an external source for authorization, configure an SQL authorization manager in the desired pipeline and reference the corresponding SQL realm name in the authorization manager.
The authorization manager also lets you define whether you want to use roles and/or user-specific permissions. Based on the configuration, the ESE uses different authorization variables. These variables can be set and manipulated with a preprocessor before the authorization manager.
| Parameter | Type | Mandatory / Default | Description |
|---|---|---|---|
|
String |
References the SQL realm from which the authentication data is drawn. |
|
|
Boolean |
|
If this parameter is set to true, the ESE uses user-specific permissions. |
|
Boolean |
|
If this parameter is set to true, the ESE uses role permissions. |
Using Role Permissions
If you want to use role permissions, set <use-authorization-role-key> to true.
The variable authorization-role-key must be set, so that the ESE can query the corresponding role and its permissions from the database.
<enterprise-security-extension>
<!-- add realms configuration -->
<pipelines>
<pipeline>
<!-- add authentication preprocessors if necessary -->
<!-- add an authentication manager -->
<!-- add authorization preprocessors if necessary -->
<sql-authorization-manager>
<realm>sql-realm-name</realm>
<use-authorization-key>false</use-authorization-key>
<use-authorization-role-key>true</use-authorization-role-key>
</sql-authorization-manager>
</pipeline>
</pipelines>
</enterprise-security-extension>To ensure that the ESE finds the authorization information in the database, the layout of the database must be in accordance with the following database tables from the SQL database structure:
-
Permissions are defined in the 'permissions' table.
-
Specific roles are defined in the 'roles' table.
-
Permissions that are assigned to each role are specified in the 'role_permissions' table.
-
User roles are assigned in the 'user_roles' table.
| We recommend that you use role permissions rather than of user-specific permissions. |
Using User-specific Permissions
If you want to use user-specific permissions, set <use-authorization-key> to true.
The variable authorization-key must be set, so that the ESE can query the corresponding user-specific permissions from the database.
<enterprise-security-extension>
<!-- add realms configuration -->
<pipelines>
<pipeline>
<!-- add authentication preprocessors if necessary -->
<!-- add authentication manager -->
<!-- add authorization preprocessors if necessary -->
<sql-authorization-manager>
<realm>example-backend</realm>
<use-authorization-key>true</use-authorization-key>
<use-authorization-role-key>false</use-authorization-role-key>
</sql-authorization-manager>
</pipeline>
</pipelines>
</enterprise-security-extension>To ensure that the ESE finds the authorization information in the database, the layout of the database must be in accordance with the following database tables from the SQL database structure:
-
Permissions are defined in the 'permissions' table.
-
User-specific permissions are stored in the 'user_permissions' table.
SQL Database Setup
SQL Driver Installation
Each SQL realm must create a JDBC database connection to the configured database instance. To create the connection, a database-specific JDBC Driver is required.
Because the license requirements of the different JDBC driver implementations differ widely, the ESE does not come prepackaged with a driver.
To provide the ESE with the necessary JDBC driver, simply drop the corresponding jar file into the
<ESE-Home>/drivers/jdbc directory.
Include all of the JDBC driver jar files that you need, so that the drivers can be loaded at extension start.
The following table offers links to drivers and additional information:
| Database | Download Link | Minimum Version |
|---|---|---|
PostgreSQL and Amazon Aurora |
JDBC 4.2 |
|
MySQL, MariaDB, and Amazon Aurora |
Connector/J 8.0 |
|
MSSQL and Azure SQL |
JDB Driver 7.2 |
SQL Database Setup
For the ESE to work properly, the SQL database has to have a certain schema. This structure is described in detail below.
To facilitate database setup, the ESE provides an SQL setup snippet for every supported SQL database.
This snippet creates a database with all the required tables and columns.
The SQL setup snippet can be found in the <ESE-Home>/sql/<ESE-Version> folder as a text file.
By copying the content and inserting it into your database management system or using it directly as SQL script it generates the needed structure automatically.
Once the necessary tables are created, use the usual SQL commands to fill the tables with the data of your clients as desired.
To help you store the passwords in an appropriate format, the ESE provides a CLI tool. For example, use the CLI tool to create SQL INSERT statements for the 'users' table and ensure that all passwords are stored in a way that the ESE can process. Of course, you can process passwords and store them in the database without the provided CLI tool. The cryptography section explains how the ESE processes passwords. Always ensure that the passwords are stored in a way so that the ESE can validate them.
If you already have a supported SQL database, simply verify that your data is stored in a way that the ESE can work with. If you do not have a matching SQL structure, this SQL view documentation shows a way to create a database view that is in accordance with the required database structure of the ESE.
SQL Database Structure

If you use the provided sql scripts to set up your database in version 1.2 or later, two additional columns are added to each table: created_at and updated_at.
These columns are of the appropriate database-specific data type for storing an uniquely identifiable timestamp.
The entry created_at is always set to the time the database record was created.
The entry updated_at is always set to the time of the last change to the database record.
There is no need for you to interact with either created_at or updated_at manually.
|
| Column | Data Type | Description |
|---|---|---|
|
Text |
Primary Key, Unique, Not Null |
|
Text |
Base64 Encoded raw byte array |
|
Integer |
Not Null |
|
Text |
Not Null |
|
Text |
Not Null |
| Column | Data Type | Description |
|---|---|---|
|
Serial |
Primary Key, Unique, Not Null |
|
Text |
Unique, Not Null |
|
Text |
| Column | Data Type | Description |
|---|---|---|
Integer |
Primary Key |
|
Integer |
Primary Key |
| Column | Data Type | Description |
|---|---|---|
|
Serial |
Primary Key |
|
Text |
Not Null |
|
Boolean |
Default false, Not Null |
|
Boolean |
Default false, Not Null |
|
Boolean |
Default false, Not Null |
|
Boolean |
Default false, Not Null |
|
Boolean |
Default false, Not Null |
|
Boolean |
Default false, Not Null |
|
Boolean |
Default false, Not Null |
|
Text |
| Column | Data type | Description |
|---|---|---|
Integer |
Primary Key, Not Null |
|
Integer |
Primary Key, Not Null |
| Column | Data Type | Description |
|---|---|---|
Integer |
Primary Key, Not Null |
|
Integer |
Primary Key, Not Null |
SQL Database Structure for Control Center Access Control
The ESE-access control feature for your control center requires additional tables in your SQL database. If you only want to authenticate or authorize MQTT clients, no additional tables are required.

If you use the provided sql scripts to set up your database in version 1.2 or later, two additional columns are added to each table: created_at and updated_at.
These columns are of the appropriate database-specific data type for storing a uniquely-identifiable timestamp.
The entry created_at is always set to the time that the database record was created.
The entry updated_at is always set to the time of the last change to the database record.
There is no need for you to interact with either created_at or updated_at manually.
|
| Column | Data Type | Description |
|---|---|---|
|
Text |
Primary Key, Unique, Not Null |
|
Text |
Base64 Encoded raw byte array |
|
Integer |
Not Null |
|
Text |
Not Null |
|
Text |
Not Null |
| Column | Data Type | Description |
|---|---|---|
|
Serial |
Primary Key, Unique, Not Null |
|
Text |
Unique, Not Null |
|
Text |
| Column | Data Type | Description |
|---|---|---|
Integer |
Primary Key |
|
Integer |
Primary Key |
| Column | Data Type | Description |
|---|---|---|
|
Serial |
Primary Key |
|
Text |
Not Null |
|
Text |
A script to insert all supported HiveMQ permissions is provided in the sql folder or you can copy and paste the following script:
-- insert the default permissions strings that are supported by HiveMQ into the cc_permissions
insert into cc_permissions (permission_string, description)
values ('HIVEMQ_SUPER_ADMIN', 'special cc_permission, that allows access to everything'),
('HIVEMQ_VIEW_PAGE_CLIENT_LIST', 'allowed to view client list'),
('HIVEMQ_VIEW_PAGE_CLIENT_DETAIL', 'allowed to view client detail'),
('HIVEMQ_VIEW_PAGE_LICENSE', 'allowed to view license page'),
('HIVEMQ_VIEW_PAGE_TRACE_RECORDINGS', 'allowed to view trace recording page'),
('HIVEMQ_VIEW_PAGE_DROPPED_MESSAGES', 'allowed to dropped message page'),
('HIVEMQ_VIEW_PAGE_BACKUP', 'allowed to view backup page'),
('HIVEMQ_VIEW_DATA_CLIENT_ID', 'allowed to see client identifiers'),
('HIVEMQ_VIEW_DATA_IP', 'allowed to see client''s IPs'),
('HIVEMQ_VIEW_DATA_PAYLOAD', 'allowed to see message payloads'),
('HIVEMQ_VIEW_DATA_PASSWORD', 'allowed to see client''s passwords'),
('HIVEMQ_VIEW_DATA_USERNAME', 'allowed to see client''s usernames'),
('HIVEMQ_VIEW_DATA_WILL_MESSAGE', 'allowed to see client''s LWT'),
('HIVEMQ_VIEW_DATA_TOPIC', 'allowed to see client''s topics'),
('HIVEMQ_VIEW_DATA_SUBSCRIPTION', 'allowed to see client''s subscriptions'),
('HIVEMQ_VIEW_DATA_PROXY', 'allowed to see client''s proxy information'),
('HIVEMQ_VIEW_DATA_TLS', 'allowed to see client''s TLS information'),
('HIVEMQ_VIEW_PAGE_KAFKA_DASHBOARD', 'allowed to view the HiveMQ Extension for Kafka page'),
('HIVEMQ_VIEW_PAGE_RETAINED_MESSAGE_LIST', 'allowed to view retained message list'),
('HIVEMQ_VIEW_PAGE_RETAINED_MESSAGE_DETAIL', 'allowed to view retained message details'),
('HIVEMQ_VIEW_DATA_USER_PROPERTIES', 'allowed to see user properties of messages'),
('HIVEMQ_VIEW_DATA_SESSION_ATTRIBUTES', 'allowed to see session attributes of clients'),
('HIVEMQ_VIEW_DATA_CLIENT_EVENT_HISTORY', 'allowed to see the event history of clients'),
('HIVEMQ_VIEW_PAGE_SHARED_SUBSCRIPTION_LIST', 'allowed to view shared subscription list'),
('HIVEMQ_VIEW_PAGE_SHARED_SUBSCRIPTION_DETAIL', 'allowed to view shared subscription details'),
;| Column | Data type | Description |
|---|---|---|
Integer |
Primary Key, Not Null |
|
Integer |
Primary Key, Not Null |
| Column | Data Type | Description |
|---|---|---|
Integer |
Primary Key, Not Null |
|
Integer |
Primary Key, Not Null |
Supported SQL database versions
| SQL Database | Supported Versions |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
OAuth 2.0 / JWT
The HiveMQ Enterprise Security Extension enables clients to authenticate via provided JSON Web Tokens (JWT). These tokens are frequently used for authentication and authorization in HTTP-based web applications. The HiveMQ Enterprise Security Extension makes it possible to integrate JWTs into your MQTT infrastructure.
JWTs are self-contained, digitally signed collections of JSON key-value pairs (claims). Claims are provided in the payload of the JWT and are used to assert information about the bearer of the token.
The JWT can contain two types of claims. You can configure the ESE authentication manager to validate one or more claims as needed to fulfill your use case:
-
Reserved claims: Statement name and value pairs with predefined names.
-
Custom claims: Statement name and value pairs that can be defined as desired.
| Custom claims require specialized solutions to map or read and are more expensive to deserialize and validate. |
| Reserved Claim Name | Description |
|---|---|
|
The intended recipient of the JWT. This entry is the audience of the JWT. |
|
The name of the entity to which the JWT refers. This entry is the subject of the JWT. |
|
The name of the authority that provides the JWT. This entry is the issuer of the JWT. |
|
The actions for which the JWT is intended. The name of this entry can be adjusted with the |
Example JWT Payload
{
"iss": "jwt-service",
"sub": "my-mqtt-client",
"aud": "hivemq.com",
"iat": 1573567292,
"exp": 1573653692,
"scope": [
"publish",
"subscribe"
],
"service": "mqtt-broker"
}To add a trusted JWT provider, configure a <jwt-realm> in the <realms> section of your ESE configuration.
The HiveMQ Enterprise Security Extension can work with many different kinds of JWT providers.
Here are some of the popular JWT providers ESE supports:
JWT Realm
The abstraction of a JWT provider in the ESE configuration is a jwt-realm.
The JWT realm provides all of the information that the ESE needs to fetch the JSON Web Key Set (JWKS) and the optional introspection endpoint for the JWTs.
The JWKS is a set of public keys that the JWT provider issues for verification of the JWTs.
Introspection is an optional method to online verify the validity of a token, after it was issued.
<enterprise-security-extension>
<jwt-realm>
<name>jwt-provider</name>
<enabled>true</enabled>
<configuration>
<jwks-endpoint>https://jwt-service/keys</jwks-endpoint>
<jwks-default-cache-duration>1800</jwks-default-cache-duration>
<tls-trust-store>path/to/truststore.jks</tls-trust-store>
<introspection-endpoint>https://jwt-service/token/introspect</introspection-endpoint>
<simple-auth>
<username>ese</username>
<password>client-secret</password>
</simple-auth>
</configuration>
</jwt-realm>
</enterprise-security-extension>| Parameter | Type | Mandatory | Description |
|---|---|---|---|
|
URI |
Specifies the HTTP (GET) endpoint where the JWKS of the provider is located. |
|
|
Integer |
If this information is not specified by the provider in the HTTP response, this entry configures the duration that the JWKS is cached in seconds. |
|
|
If the default system-wide TLS trust store is not used, this entry specifies an alternative trust store. |
||
|
URI |
Specifies the HTTP (POST) endpoint where the JWT of the client is sent for further validation as specified in RFC-7662. |
|
|
Defines the HTTP Simple Auth parameters that are used for introspection requests from ESE to the identity server. |
TLS Trust Store
<tls-trust-store password="secret">path/to/truststore.jks</tls-trust-store>| Parameter | Type | Mandatory | Description |
|---|---|---|---|
|
File Path |
Path where the trust store is located. |
|
|
String |
Password to open the truststore. |
Simple Auth
<simple-auth>
<username>ese</username>
<password>client-secret</password>
</simple-auth>| Parameter | Type | Mandatory | Description |
|---|---|---|---|
|
String |
The username portion of the HTTP Simple Auth. This string is usually the name of the OAuth realm. |
|
|
String |
The password portion of the HTTP Simple Auth. This string is usually the OAuth client secret. |
JWT Authentication Manager
JWT is an open standard (RFC 7519) that defines a compact and self-contained way to securely transmit information as a JSON object. The information in the digitally signed JWT can be trusted and verified.
To implement custom logic for authentication with JWTs, you must configure a JWT authentication manager in your ESE configuration.
Example JWT authentication manager configuration
<jwt-authentication-manager>
<realm>jwt-backend</realm>
<!-- every tag in the configuration must contain a value. All tags except the realm name and custom claims have a default value. -->
<validation>
<!-- default: no disconnect after expiration date -->
<exp-grace disconnect-after-expiry="true">300</exp-grace>
<!-- default: false -->
<enable-introspection sampling="0.5">true</enable-introspection>
<reserved-claims>
<aud>hivemq</aud>
<sub>${mqtt-clientid}</sub>
<iss>jwt-service</iss>
<!-- scope is an OpendID Connect standard not a JWT standard -->
<scope alt="scp">publish subscribe</scope>
</reserved-claims>
<!-- only use direct match string values -->
<custom-claims>
<claim>
<name>defined-name</name>
<value>defined-value</value>
</claim>
</custom-claims>
</validation>
</jwt-authentication-manager>| Parameter | Type | Default Value | Description |
|---|---|---|---|
|
Name reference |
* |
Defines the JWT realm that the authentication manager accesses. * The realm parameter is mandatory and does not have a default value. |
|
Integer |
300 |
Defines the number of seconds before the Issued At (iat) and after the Expired (exp) in which the CONNECT can occur and the claims remain valid.
A token presented outside the time interval |
|
Boolean (XML Attribute) |
false |
Defines whether the ESE automatically disconnects the client when the token that the client bears expires. |
|
Boolean |
false |
Defines whether the ESE checks with the identity server that issued the JWT for an additional validation of the token after successful local validation. |
|
Float [0.0 .. 1.0] (XML Attribute) |
1.0 |
Sets the probability that ESE selects a token for introspection. |
|
Shows the reserved claims that are validated. |
||
|
Shows the custom claims that are validated. |
The JWT authentication manager can contain various validations. By default, every JWT authentication manager includes the following validations:
-
Signature
-
Expiration date
-
Issue date
To successfully complete a JWT authentication flow in the ESE, the provided JWT must pass all configured and default validations. Once validation is successful, the MQTT client can proceed to the authorization step of the pipeline.
The JWT authentication manager expects the token to be present in the authentication-byte-secret ESE variable.
Automatic Client Disconnection
The ESE observes the expiration date of the JWT token. If desired, you can configure the ESE to automatically disconnect clients when the JWT that the client bears expires. When the JWT token of a client expires the ESE disconnects the client.
You can also configure an expiration grace period in the JWT authentication manager of your ESE. When you configure an expiration grace period, the ESE disconnects the client after the grace period expires.
If you do not configure the ESE to disconnect clients when the JWT expires, clients with an expired token can remain connected.
| If a client connects with an additional authentication method, the ESE respects that method even if the JWT expires. |
Validation of Claims
The payload of JSON Web Tokens consists of various claims, which are key-value pairs. ESE can validate the claims against static configured values or values dynamically generated from ESE variables with the permission placeholders mechanic.
For example, the <sub>${mqtt-clientid}</sub> line in the configuration example tells the ESE to compare the value of the subject claim (sub)
with the value of the clientID in the MQTT CONNECT packet.
Reserved Claims
<reserved-claims>
<aud>hivemq</aud>
<sub>${mqtt-clientid}</sub>
<iss>jwt-service other-jwt-service</iss>
<scope alt="scp">publish subscribe</scope>
</reserved-claims>| Claim | Type | Semantic |
|---|---|---|
|
String |
The audience (aud) claim identifies the intended recipients of the JWT. A single token can have multiple audiences. The validation configuration of the JWT authentication manager must include one of the audiences that is listed in the claim. |
|
String |
The subject (sub) claim identifies the bearer of the token. The bearer is the entity the token was issued to. The sub claim must be unique in the token and an exact match to the validation configuration of the JWT authentication manager. |
|
List of Strings |
The issuer (iss) claim identifies the service that created and signed the token. Multiple instances can be configured. Only one of them must match the one in the token, which itself must be unique. |
|
List of Strings |
The scope claim specifies the intended use of the token.
All scope values that are defined in the validation configuration of the JWT authentication manager must be present in the token.
If desired, you can use the |
The JWT authentication manager of the ESE uses information from the scope claim to populate the authorization-role-key.
Information from the sub claim is used to populate the authorization-key ESE Variables.
|
Custom Claims
ESE can validate information from custom claims. Custom claims can contain a single string value of your choice. Permission placeholder substitution is performed before validation.
<custom-claims>
<claim>
<name>service</name>
<value>mqtt-broker</value>
</claim>
<claim>
<name>userName</name>
<value>${mqtt-username}</value>
</claim>
</custom-claims>| Parameter | Type | Semantic |
|---|---|---|
|
String |
The name (key) of the custom claim. |
|
String |
The value of the custom claim. |
| The ESE only requires a JWT Bearer Token. Do not put secret information in the JWT or share Identity or Refresh tokens. Although the information in the JWT cannot be altered without detection, a third party can read the information that the JWT contains. |
JWT Authentication Flow
JWTs are frequently generated and consumed in authentication flows. Because these flows require HTTP mechanics, it is not possible to implement a JWT authentication directly in MQTT. Before an MQTT client starts a JWT authentication flow with the ESE, the client must aquire a token from the JWT provider of your choice.
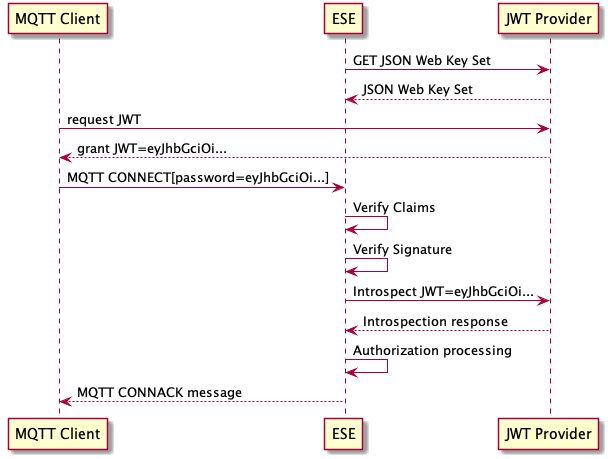
-
The HiveMQ ESE gets the JSON Web Key Set (JWKS) from the JWT provider that is defined in the JWT realm of your ESE configuration.
-
The MQTT client gets a JWT from the selected JWT provider.
-
The MQTT client sends a CONNECT packet to HiveMQ with the provided JWT in the password field.
-
The HiveMQ ESE verifies the claims in the JWT that the MQTT client provided.
-
The HiveMQ ESE validates the digital signature of the JWT against the JWKS from the JWT provider.
-
Optionally, HiveMQ introspects the JWT against the JWT provider.
-
Successfully authenticated MQTT clients proceed to the authorization stage of the HiveMQ ESE pipeline.
-
After successful authorization processing, HiveMQ ESE sends the MQTT client a CONNACK packet.
| If the authentication fails, the MQTT client is not allowed to connect. The HiveMQ ESE sends a CONNACK with an error code and closes the TCP connection. |
Lightweight Directory Access Protocol (LDAP)
The Lightweight Directory Access Protocol, LDAP for short, is an open standard protocol for interacting with directory servers. LDAP is widely-used to authenticate and store information about users, groups, and applications.
The current standard, LDAPv3, is defined in RFC 4510.
The HiveMQ Enterprise Security Extension (ESE) can work with any standard-compliant LDAP server. For example:
-
Microsoft Active Directory Domain Services (AD DS) and Microsoft Active Directory Lightweight Directory Services (AD LDS), which was previously named Active Directory Application Mode (ADAM)
-
Apache Directory Studio (ApacheDS)
Basic LDAP Concepts
Unlike SQL databases that store information in structured matrices (tables), LDAP stores information in a hierarchical data structure (tree). The LDAP data structure is called a Directory Information Tree (DIT).
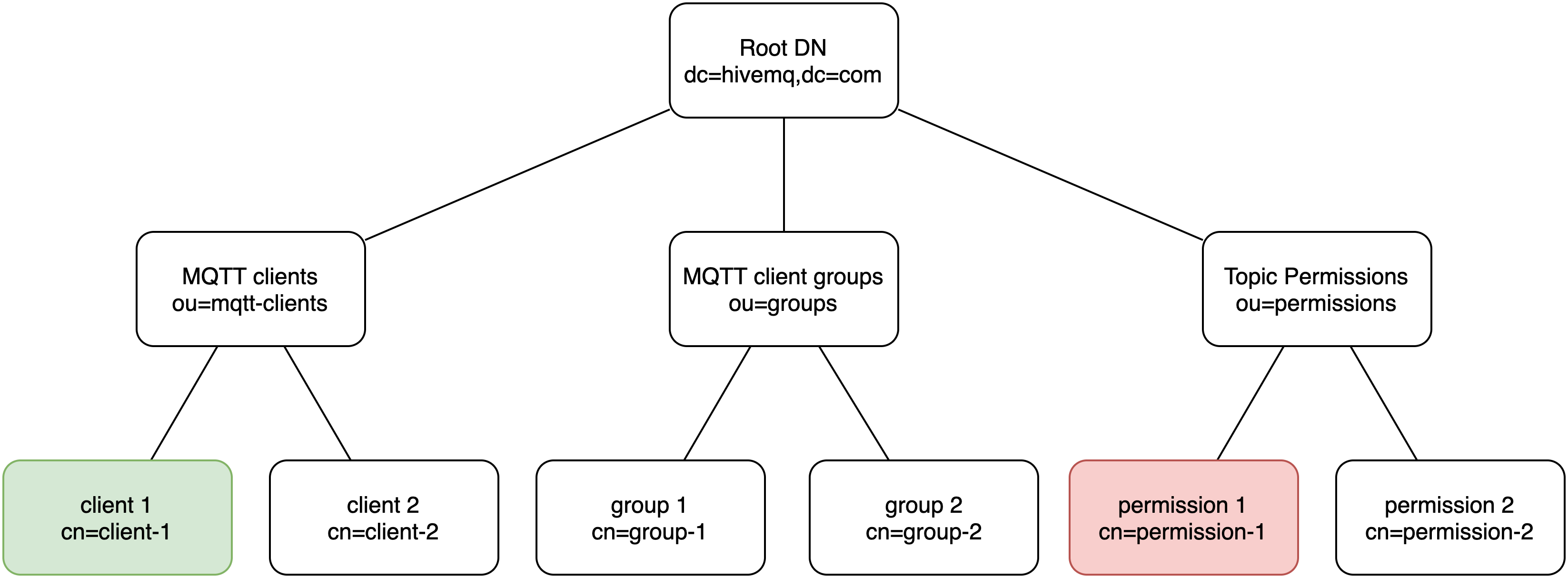
Entries
Each node in an LDAP tree is called an entry. An LDAP entry is a collection of information about a particular object. Entries have three main components:
Distinguished Names (DN)
The distinguished name (DN) of an entry specifies the name and position of the entry in the LDAP tree. In an LDAP tree, each DN is unique and describes the fully qualified path to a particular entry. DN are made up of a sequence of zero or more comma-separated components called relative distinguished names (RDN).
Relative Distinguished Names (RDN)
A relative distinguished name (RDN) is a component of a DN. In an LDAP tree, RDN describe the partial path to an entry relative to another entry in the tree. Each RDN contains at least one attribute name-value pair.
In the DIT example diagram, the DN of the green client consists of the following RDN: cn=client-1,ou=mqtt-clients,dc=hivemq,dc=com.
The DN of the red permission consists of these RDN: cn=permission-1,ou=permissions,dc=hivemq,dc=com.
cn stands for common name, ou organizational unit, and dc the domain component.
| Distinguished names are written LEFT to RIGHT. Although a DN is similar to an absolute path on a filesystem, filesystem paths typically start with the root of the filesystem and descend the tree from left to right. In LDAP, a DN ascends the tree from left to right. The base DN is on the right. |
LDAP Association
There are two main ways to associate entries in LDAP:
-
Direct Reference: Uses information from attributes in the distinguished name of an entry to create a direct association.
-
Descent: Uses the position of the entry in the LDAP tree to create association through a subtree.
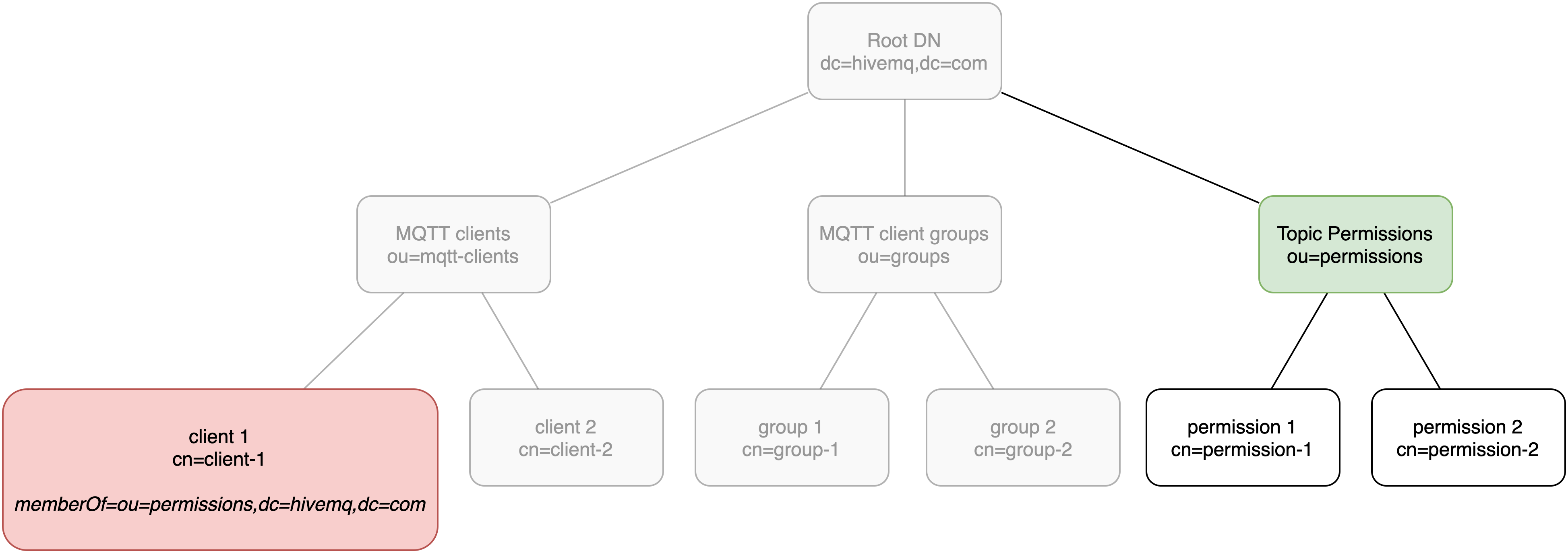
| Direct reference in LDAP is similar to the way foreign keys are used in an SQL database. |
In the direct reference diagram, the RDN of client 1 includes a memberOf attribute that contains the DN of Topic Permissions.
The memberOf attribute automatically associates Topic Permissions to client 1 with a direct reference.
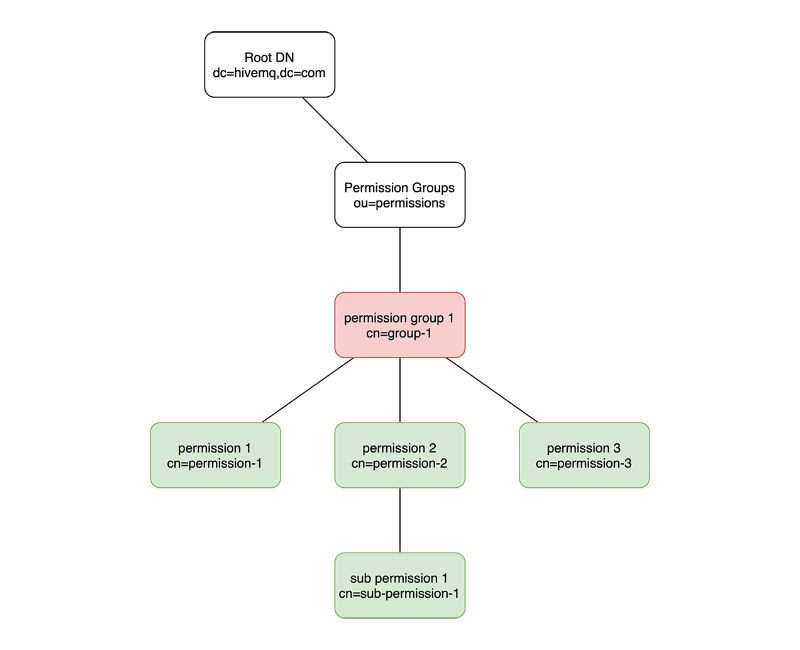
In the subtree/descent diagram, descent is used to give permission group 1 all of the permissions that appear below permission group 1 in the tree.
LDAP Realms
In the ESE configuration, the abstraction of an LDAP server is an ldap-realm.
The LDAP realm provides all of the information that the ESE needs to connect to the LDAP server, perform the necessary bind requests, and execute LDAP searches.
Bind requests are the way that the LDAP protocol performs authentication.
LDAP search operations are equivalent to an SQL query. Caching on data returned from the LDAP server is also performed in the same manner.
<ldap-realm>
<name>my-ldap-server</name>
<enabled>true</enabled>
<configuration>
<servers>
<ldap-server>
<host>host-1</host>
<port>389</port>
</ldap-server>
<ldap-server>
<host>host-2</host>
<port>389</port>
</ldap-server>
</servers>
<tls>tcp</tls>
<tls-trust-store>/path/to/truststore.jks</tls-trust-store>
<base-dn>dc=hivemq,dc=com</base-dn>
<simple-bind>
<rn>cn=ese,cn=hivemq</rn>
<userPassword>password</userPassword>
</simple-bind>
</configuration>
</ldap-realm>| Parameter | Type | Mandatory | Description |
|---|---|---|---|
|
Specifies one or more LDAP servers that the ESE accesses. |
||
|
Enum |
Specifies the transport security type that the ESE uses to connect to the LDAP servers. Possible settings are: |
|
|
Specifies an alternative trust store when the default system-wide TLS trust store is not used. |
||
|
LDAP distinguished name |
Specifies the starting point that the ESE uses in the LDAP tree. All ESE searches and bind requests are relative to this base DN. |
|
|
Defines the simple bind parameters that the ESE uses to authenticate itself to the LDAP servers. |
LDAP Server
The LDAP server setting configures a single LDAP instance. If you run LDAP in a clustered environment, the setting configures multiple instances. During runtime, the ESE accesses each instance in a round-robin fashion.
<ldap-server>
<host>my.ldap.host</host>
<port>389</port>
</ldap-server>| Parameter | Type | Mandatory | Description |
|---|---|---|---|
|
Domain name or IP Address |
The network address where the LDAP server is located. |
|
|
Integer |
The port on which the LDAP server listens. This port is usually based on the type of transport security that is used. The default port setting is 389 (TCP). |
Simple Bind
<simple-bind>
<rdns>cn=ese,cn=broker</rdns>
<userPassword>password</userPassword>
</simple-bind>| Parameter | Type | Mandatory | Description |
|---|---|---|---|
|
String |
The relative distinguished names (RDN) of the base DN that the ESE uses to bind to the LDAP server. Make sure that this DN is bindable and has the necessary rights to search for the users and permissions. |
|
|
String |
The password portion that the ESE uses to perform a simple bind operation on the LDAP server. |
LDAP Authentication Manager
To implement custom logic for authentication over LDAP, you must configure an LDAP authentication manager in your ESE configuration.
<ldap-authentication-manager>
<realm>my-ldap-server</realm>
<clients-rdns>ou=mqtt-clients,ou=iot-services</clients-rdns>
<uid-attribute>cn</uid-attribute>
<required-object-class>hmq-mqttClient</required-object-class>
</ldap-authentication-manager>| Parameter | Type | Mandatory | Description |
|---|---|---|---|
|
String |
The LDAP realm on which this authentication manager is based. |
|
|
LDAP directory name. |
The starting RDN where ESE begins searches for client authentication information. |
|
|
String |
The unique LDAP attribute that is used to identify every entry in the subtree of client RDNs.
The default setting is |
|
|
String |
Configures an object class that all entries which are considered for authentication purposes, must have. The default is none. |
First, the LDAP authentication manager does an LDAP search for the entry that has a uid equals to the authentication-key. Next, LDAP authentication manager binds to the returned DN with the authentication-byte-secret.
After successful authentication, the LDAP authentication manager sets the ESE variable authorization-key to the DN of the client entry that is found.
If the found entry contains memberOf attributes, the authorization-role-key variable is set to the grouping information that the memberOf attributes provide.
LDAP Authorization Manager
To implement custom logic for authorization over LDAP, you must configure an LDAP authorization manager in your ESE configuration.
<ldap-authorization-manager>
<realm>my-ldap-server</realm>
<directory-descent>false</directory-descent>
<use-authorization-key>true</use-authorization-key>
<use-authorization-role-key>true</use-authorization-role-key>
</ldap-authorization-manager>The LDAP authorization manager requires full DNs in the ESE authorization variables.
| Parameter | Type | Mandatory | Description |
|---|---|---|---|
|
Boolean |
Specifies whether permissions are searched by descent (instead of direct reference).
The default setting is |
|
|
Boolean |
Specifies whether the |
|
|
Boolean |
Specifies whether the |
LDAP Server Setup
-
Entries used for authentication must be bindable through simple bind requests
-
Special object classes and attributes are only needed for authorization
-
Scripts for the new LDAP object classes and attributes that the ESE uses are available in
[ese-dir]/scripts/ldap/[ese-version](AD, ApacheDS, OpenLDAP, rfc compliant) -
The configuration of an LDAP server is specific to the individual server that is used. Always follow the procedures and best practices that are associated with the selected server.
-
To enable direct reference, you must add the auxiliary class
hmq-mqttClientorhmq-controlCenterUserto the desired user or group object -
All LDAP object classes and attributes that are used in the ESE have a unique object identifier (OID) that is registered at the Internet Assigned Numbers Authority (IANA)
Object Classes
Object classes indicate what type of object an LDAP entry represents.
Every LDAP entry must have exactly one structural object class and can have zero or more auxiliary object classes.
Each object class has a unique name and defines which attributes are mandatory (Must) or optional (May) for a particular entry.
Since the LDAP schema that the ESE uses has only one structural object class, all entries can include the hmq-mqttPermission object class.
| Name | Type | Mandatory Attributes | Optional Attributes | Description |
|---|---|---|---|---|
|
Structural |
|
hmq-qualityOfService, hmq-publish, hmq-subscribe, hmq-retain, hmq-share, hmq-sharedGroup, description, cn |
Defines the authorization data for an MQTT topic. If multiple permissions for the same topic string are used, include the common name in the distinguished name of the entry. |
|
Auxiliary |
|
Authorizes an MQTT client with one or more permissions. If attached to a group of names or group of unique names, the entry can represent multiple clients that share an RBAC role. |
|
|
Auxiliary |
|
Defines which control center views a control center user is granted. |
Attributes
Attributes hold the data for an LDAP entry.
Each attribute has a unique name, a unique object identifier (OID), and is a member of one or more object classes.
Since the hmq-topicFilter attribute is a required element of the mandatory hmq-mqttPermission object class, all entries include this attribute.
In the LDAP schema that the ESE uses, each LDAP attribute begins with 1.3.6.1.4.1.54795. followed by a unique sequence.
For example, the OID of the hmq-topicPermission attribute is 1.3.6.1.4.1.54795.2.3.1.
The unique portion of the OID is emphasized in the following attributes table.
|
| Name | Identifier | Description |
|---|---|---|
|
1.3.6.1.4.1.54795.2.3.1 |
The topic permission attribute represents all permissions that are associated with a specific MQTT topic. |
|
1.3.6.1.4.1.54795.2.3.2 |
The topic filter string that determines to which topics the topic permission applies. The topic permission applies to all topic-strings that are matched by the topic filter. |
|
1.3.6.1.4.1.54795.2.3.9 |
The permission string for the HiveMQ Control Center. |
|
1.3.6.1.4.1.54795.2.3.3 |
The quality of service level (QoS) to which the topic permission applies. Possible values are 0, 1, and 2. |
|
1.3.6.1.4.1.54795.2.3.4 |
The publish topic to which the topic permission applies. The topic must match the topic filter. |
|
1.3.6.1.4.1.54795.2.3.5 |
The subscribe topic to which the topic permission applies. The topic must match the topic filter. |
|
1.3.6.1.4.1.54795.2.3.6 |
The retained messages to which the topic permission applies. The topic must match the topic filter. |
|
1.3.6.1.4.1.54795.2.3.7 |
The shared subscriptions to which the topic permission applies. The topic must match the topic filter. |
|
1.3.6.1.4.1.54795.2.3.8 |
The shared group ($share/<group>/topic) to which the topic permission applies. This attribute is only relevant when the hmq-share attribute (OID 1.3.6.1.4.1.54795.2.3.7) is set to TRUE. |
Access Log
The access log provides a single, unified log for tracking security-relevant data. This log has several use cases:
-
You can audit all accesses that the ESE grants retroactively.
-
Your intrusion-prevention software (for example, Fail2Ban) can use the access log to create firewall rules.
-
The chronological records of the access log can provide valuable information for the post-mortem of a data breach.
The access log shows you precisely who was granted access to HiveMQ, what kind of access occurred, and when the access was granted. The timezone of events in the access log is always Coordinated Universal Time (UTC).
The following is a good start for a fail-regex: ^ - authentication-failed - Client failed authentication: ID [^\s]+, IP <HOST>, reason \“((authorization timed out)|(unknown authentication key or wrong authentication secret)|(authentication timed out)|(other))\“\.$
|
Access Events
The three primary access events are Authentication Failed, Authentication Succeeded, and Authorization Succeeded. Each of these events provides the public client IP address and the MQTT client ID of the connecting client.
| Event Type | Logged Values | Log Statement |
|---|---|---|
Authentication Failed |
|
|
Authentication Succeeded |
|
|
Authorization Succeeded |
|
|
Authentication Failed
This event triggers when an MQTT client does not pass the ESE authentication and is not allowed to connect to HiveMQ. Each Authentication Failed event provides one of the following reasons for the failure:
| Reason | Description | Corresponding Metrics |
|---|---|---|
|
The client cannot be authenticated against the information that the configured realm of the authentication manager provided |
|
|
The process timed out during the authentication step of the pipeline |
|
|
The process timed out during the authorization step of the pipeline |
|
|
Something exceptional happened during the process.
In this case, you can look for more information in the DEBUG output of the |
|
Authentication Succeeded
This event triggers when an MQTT client passes the ESE authentication successfully.
These events correspond to the authentication-succeeded metric.
Authorization Succeeded
This event triggers after an MQTT client is granted permissions. The event references the Topic Permissions that the client is granted in the following format:
Permission{topicFilter='<topic-string>', qos=[<0, 1, 2>], activity=[<publish, subscribe>], retainedPublishAllowed=<true|false>, sharedSubscribeAllowed=<true|false>, sharedGroup='<group-id>', from='<source>'}.
The <source> in the reference is dependent on the type of authorization manager that you use.
For an SQL authorization manager, the source can either be the roles.name or the
users.username that the permission is associated with.
Access Log File
By default, the access log writes to the <HiveMQ Home>/log/access/access.log.
You can customize this path in the ESE configuration file.
The HiveMQ access log is a rolling log file.
Once per day at midnight, the old access-log files are automatically compressed with the gzip algorithm and archived with the filename access.<yyyy-MM-dd>.log.gz.
For example, after two days of operation the access folder contains the following files:
├─ access.2019-07-04.log.gz ├─ access.2019-07-05.log.gz └─ access.log
| The ESE never deletes the access log files that are archived. If you need to remove old access logs regularly, you must take additional action. For example, set up a scheduled cron job to alleviate data protection concerns or storage constraints. |
Access Log Configuration
In the enterprise-security-extension.xml file, you can use the optional <access-log> tag to configure the behavior of the access log.
<access-log>
<enabled>true</enabled>
<file-name>access</file-name>
<sub-folder>access</sub-folder>
<write-through>false</write-through>
</access-log>| Parameter | Type | Description | Default |
|---|---|---|---|
|
Boolean |
Enables or disables the writing of access events to the access log file |
|
|
String |
The name of the access log file. The suffix |
|
|
String |
The name of the subfolder in the |
|
|
Boolean |
Enables or disables also writing access events to the |
|
Control Center Access Control
The ESE provides access control for the HiveMQ Control Center. You can use both fine-grained access control that is based on user permissions and role-based access control (RBAC).
Requirements for Control Center Access Control
-
HiveMQ Enterprise Security Extension 1.2.0 or higher
-
HiveMQ Enterprise Edition 4.2.0 or higher
Control Center Pipeline
Similar to the authentication and authorization of MQTT clients, the handling of control-center users is done in a separate pipeline: the <control-center-pipeline>.
This special ESE pipeline works like a listener pipeline for MQTT clients, but omits authentication and authorization preprocessing and does not require transformation of ESE variables.
The control center pipeline uses the User form of the login page as the authentication-key and authorization-key.
After the Password form is decoded with the UTF8 codec, this information is used as the authentication-byte-secret.

<enterprise-security-extension>
<pipelines>
<!-- only one <control-center-pipeline> allowed -->
<!-- secure access to the control center -->
<control-center-pipeline>
<!-- authenticate over a sql db -->
<sql-authentication-manager>
<realm>postgres-backend</realm>
</sql-authentication-manager>
<!-- authorize over a sql db -->
<sql-authorization-manager>
<realm>postgres-backend</realm>
<use-authorization-key>true</use-authorization-key>
<use-authorization-role-key>true</use-authorization-role-key>
</sql-authorization-manager>
</control-center-pipeline>
</pipelines>
</enterprise-security-extension>| Refer to the description of each realm to learn how to enable access control for the control center from the desired realm. |
Control Center Permissions
To implement fine-grained access control for your control center, you assign specific control-center permissions to your users. If desired, you can assign a set of control-center permissions to a role. All users with a specific role are granted the permissions that are assigned to the role. Role-based access control can simplify permission management and increase performance.
The following permissions are available for the HiveMQ control center:
| Permission | Description |
|---|---|
HIVEMQ_SUPER_ADMIN |
Allows the user to access everything in your control center. This special permission is the default role for users in the HiveMQ config.xml. |
HIVEMQ_VIEW_PAGE_CLIENT_LIST |
Allows the user to view the client list on your control center |
HIVEMQ_VIEW_PAGE_CLIENT_DETAIL |
Allows the user to view client details on your control center |
HIVEMQ_VIEW_PAGE_LICENSE |
Allows the user to view the license information on your control center |
HIVEMQ_VIEW_PAGE_TRACE_RECORDINGS |
Allows the user to view trace recordings on your control center |
HIVEMQ_VIEW_PAGE_DROPPED_MESSAGES |
Allows the user to view dropped messages on your control center |
HIVEMQ_VIEW_PAGE_RETAINED_MESSAGE_LIST |
Allows the user to view the retained messages list on your control center |
HIVEMQ_VIEW_PAGE_RETAINED_MESSAGE_DETAILS |
Allows the user to view the retained messages details on your control center |
HIVEMQ_VIEW_PAGE_BACKUP |
Allows the user to view backup information on your control center |
HIVEMQ_VIEW_PAGE_KAFKA_DASHBOARD |
Allows the user to view the dashboard of the HiveMQ Enterprise Extension for Kafka. |
HIVEMQ_VIEW_DATA_CLIENT_ID |
Allows the user to view client identifiers on your control center Lack of this permission has the following result:
|
HIVEMQ_VIEW_DATA_IP |
Allows the user to view client IP information in your control center Lack of this permission has the following result:
|
HIVEMQ_VIEW_DATA_PAYLOAD |
Allows the user to view message payloads on your control center Lack of this permission has the following result:
|
HIVEMQ_VIEW_DATA_PASSWORD |
Allows the user to view client passwords in your control center Lack of this permission has the following result:
|
HIVEMQ_VIEW_DATA_USERNAME |
Allowed to see client’s usernames. Lack of this permission has the following result:
|
HIVEMQ_VIEW_DATA_WILL_MESSAGE |
Allows the user to view the LWT of clients on your control center Lack of this permission has the following result:
|
HIVEMQ_VIEW_DATA_TOPIC |
Allows the user to view the PUBLISH and SUBSCRIBE topics of clients on your control center Lack of this permission has the following result:
|
HIVEMQ_VIEW_DATA_SUBSCRIPTION |
Allows the user to see client subscriptions on your control center Lack of this permission has the following result:
|
HIVEMQ_VIEW_DATA_PROXY |
Allows the user to view the proxy information of clients on your control center Lack of this permission has the following result:
|
HIVEMQ_VIEW_DATA_TLS |
Allows the user to view the TLS information of clients on your control center Lack of this permission has the following result:
|
HIVEMQ_VIEW_DATA_USER_PROPERTIES |
Allows the user to view the User Properties information of MQTT5 messages |
HIVEMQ_VIEW_DATA_SESSION_ATTRIBUTES |
Allows the user to view Session Attributes of MQTT clients. Lack of this permission has the following result:
|
HIVEMQ_VIEW_DATA_CLIENT_EVENT_HISTORY |
Allows the user to view the Event History of clients Lack of this permission has the following result:
|
HIVEMQ_VIEW_PAGE_SHARED_SUBSCRIPTION_LIST |
Allows the user to view the Shared Subscription list on your control center |
HIVEMQ_VIEW_PAGE_SHARED_SUBSCRIPTION_DETAIL |
Allows the user to view Shared Subscription details on your control center |
Monitoring
The ESE exposes several metrics over the standard HiveMQ monitoring interface.
All HiveMQ Enterprise Security Extension metrics start with the prefix com.hivemq.extensions.ese.
The following table lists each metric that ESE exposes.
For increased readability, the com.hivemq.extensions.ese. prefix is omitted in the tables.
For more information on HiveMQ metrics, see metric types.
| Metric (without prefix) | Type | Description |
|---|---|---|
|
|
Shows the total number of incoming MQTT client connection attempts that the ESE processes |
|
|
Shows the total number of successful authentication requests |
|
|
Shows the total number of successful authorization requests |
|
|
Shows the total number of unsuccessful authentication requests |
|
|
Shows the total number of authentication requests that failed due to unknown authentication keys |
|
|
Shows the total number of authentication requests that failed due to incorrect authentication secrets |
|
|
Shows the total number of authentication requests that failed due to timed-out authentications |
|
|
Shows the total number of authentication requests that failed due to timed-out authorizations |
|
|
Shows the total number of authentication requests that failed due to other reasons |
Each SQL realm has its own metrics. The name of the realm is included in the metric name.
| Metric (without prefix) | Type | Description |
|---|---|---|
|
|
Shows the rate of requests for role-based permission data that are handled from the ESE cache. The rate is provided in requests per a pre-defined time interval for the specified SQL realm. |
|
|
Shows the rate of requests for user-based permission data that are handled from the ESE cache. The rate is provided in requests per a pre-defined time interval for the specified SQL realm. |
|
|
Shows the duration and frequency of requests for authorization data from the specified SQL realm |
|
|
Shows the duration and frequency of requests for authentication data from the specified SQL realm |
|
|
Shows the rate of requests for user-based permission data that are handled from the ESE cache. The rate is provided in requests per a pre-defined time interval for the specified SQL realm. |
ESE exposes several metrics about the usage of JSON Web Tokens (JWT).
Most of the JWT metrics are realm-specific and include the realm name in the metric name.
| Metric (without prefix) | Type | Description |
|---|---|---|
|
|
Shows the total number of parsed JWTs. This includes JWTs parsed by the JWT preprocessor. |
|
|
Shows the rate of successfully validated JWTs for the specified realm. |
|
|
Shows the rate of unsuccessfully validated JWTs for the specified realm. |
|
|
Shows the rate of token introspection requests against the specified realm. |
|
|
Shows the duration and frequency of introspection requests against the specified realm. |
| Metric (without prefix) | Type | Description |
|---|---|---|
|
|
Shows the duration of queries for authentication data from LDAP realms. |
|
|
Shows the duration of LDAP bind requests to authenticate users. |
|
|
Shows the number of failed searches for LDAP users (MQTT and control center). |
|
|
Shows the duration of LDAP searches for hmq-mqttPermissions. |
|
|
Shows the rate of requests for LDAP role permissions that are handled from the ESE cache. |
|
|
Shows the rate of requests for LDAP user permissions that are handled from the ESE cache. |
|
|
Shows the rate of requests for hmq-mqttPermissions that are handled from the ESE cache. |
|
|
Shows the number of failed searches for MQTT permissions. |
|
|
Shows the number of failed searches for control center permissions. |
|
|
Shows the rate of requests for authentication credentials that are handled from the ESE cache. |
Support
If you need help with the HiveMQ Enterprise Security Extension or have suggestions on how we can improve the extension, please contact us at contact@hivemq.com.