Data Transformations in HiveMQ Data Hub
IoT devices can send a wide range of data sets.
As a result, the MQTT data you receive often contains diverse data points, formats, and units.
Data transformation is sometimes necessary to bring diverse data into a common format that an application can understand and process.
The HiveMQ Data Hub transformation feature gives you the ability to add custom JavaScript-based transformation functions to your Data Hub data policies. For more information, see Modify Your MQTT Data In-Flight with Data Transformation.
Configuration
| On Linux systems, HiveMQ Data Hub scripting requires GLIBC version 2.29 or higher. |
| Before you disable the Data Hub scripting feature, you must delete all Data Hub transformation scripts that are currently present in your HiveMQ deployment. Failure to delete existing scripts before disabling the scripting feature can prevent HiveMQ startup. |
HiveMQ Data Hub’s scripting engine can be configured as follows in the config.xml:
JavaScript
JavaScript is currently one of the most widely adopted programming languages worldwide. It is a well-established and highly versatile language that offers ease of use and a vast ecosystem of resources that can simplify development. In addition to the support of a large and active community of developers, JavaScript is a dynamically typed language with a rich set of built-in functions that cover a wide range of tasks.
JavaScript is particularly well-suited to processing and transforming JSON payloads, due to its ability to natively work with JSON datatypes. All MQTT messages that are provided to transformation scripts are first deserialized into JSON objects for ease-of-use.
Data Hub supports recent JavaScript features in line with ECMAScript 2024. For more information on using JavaScript and its available functionality, see Mozilla Developer Network.
| Transformation scripts run in a pure JavaScript sandboxed environment and do not have access to functionality specific to web browsers or other runtimes such as Node.js. Additionally, asynchronous functionality is currently not supported. |
Transformation Scripting with JavaScript
HiveMQ Data Hub offers an easy-to-use interface for processing and transforming incoming MQTT messages using JavaScript.

The diagram illustrates an incoming MQTT PUBLISH message in JSON format with a payload containing a single value field.
The JavaScript function in the center is the source code for a transformation script that modifies the incoming message.
The resulting JSON object on the right contains a new payload with a transformed value field and a new timestamp field.
Transformation API
Transformation scripts must implement the following API:
function init(initContext) {
// Initialization code
}
function transform(publish, context) {
// Transformation code
return publish;
}The init function is optional and can be omitted if you do not need to configure the script upon creation.
The transform function is required.
The functions must be defined with exactly these names.
A script can define other functions in addition to init and transform. For example, utility functions used for validating data.
A script can also be used to define top-level variables and classes.
To enable concurrent execution and improved performance, Data Hub can create multiple instances of the same script. Each instance runs in a separate isolated JavaScript execution environment. Therefore, scripts should not rely on global variables to retain information across executions. If stateful transformations are required, rely on the client connection state API.
| The client connection state feature is currently only available in HiveMQ Edge. This feature will become available in HiveMQ Enterprise version 4.38. |
transform Function
The transform function is executed for every MQTT PUBLISH message that is provided to the transformation script.
See Transformations in Data Policies for more information about how to include transformation scripts in data policies to control when they are executed.
The transform function takes two parameters:
-
publish: The incoming MQTT PUBLISH message to be transformed. -
Contextobject: Additional metadata about the message as well as branches and states that have been defined in theinitfunction.
The transform function must return a Publish object that is the transformed MQTT message.
Publish Object
| Field | Type | Required | Description |
|---|---|---|---|
|
String |
The MQTT topic that is currently specified for this PUBLISH packet. |
|
|
Number |
The Quality of Service level for the PUBLISH packet. Possible values are |
|
|
Boolean |
Defines whether the PUBLISH packet is a retained message. Possible values are |
|
|
Array of Object |
A list of all user properties of the MQTT 5 PUBLISH packet. Each user property is an object a |
|
|
any |
A JSON-serializable value representing the payload of the MQTT message. For more information, see Deserialization & Serialization. |
All properties of the Publish object can be edited.
If the topic property of a Publish object is modified, further data policies are only applied to the message if they have topic filters that match the newly transformed topic.
Publish object in a JavaScript functionfunction transform(publish, context) {
const newPublish = {
payload: { value: "42" },
topic: "universal_topic",
userProperties: [ { name: "transformed", value: "true" } ],
retain: false,
qos: 1,
}
return newPublish;
}This first example creates a new Publish object and fills all properties with appropriate values.
Publish object with some fields omittedfunction transform(publish, context) {
const newPublish = {
payload: { value: "42" },
topic: "universal_topic",
}
return newPublish;
}This second example omits the optional properties from the Publish object.
The transformed message has the same QoS and retained message flag as the original message and no user properties.
Context Object
The Context object contains additional information about the origin of the incoming message.
It also provides access to any branches and client connection states that are defined in the init function of the same script.
| Field | Type | Description |
|---|---|---|
|
Object |
A JSON object containing the arguments provided to the script in a data policy. These are defined in the |
|
String |
The |
|
String |
The |
|
Object |
All |
|
Object |
All |
Context object in a JavaScript functionfunction transform(publish, context) {
const payload = publish.payload;
publish.payload = {
value: payload.value + context.arguments['offset'],
fromClient: context.clientId,
}
return publish;
}This example script adds a new fromClient field to the payload with the value of the clientId from the context object.
It also modifies the value field according to the arguments the data policy provides.
Init Function
The init function is used to configure the transformation script, including defining any branches and client connection states that are required for use in the transform function.
The init function is only called once when a new version of a transformation script is created.
If any JavaScript errors occur during the execution of this function, the creation of the script fails.
This function takes a single parameter called the InitContext object.
The init function is not expected to return any values.
InitContext Object
The InitContext object contains methods for configuring the transformation script.
| Field | Type | Description |
|---|---|---|
|
Function |
The |
|
Function |
The |
InitContext object in the init functionlet lastPublishTimestampState, publishCountState;
function init(initContext) {
initContext.addBranch("metrics");
lastPublishTimestampState = initContext.addClientConnectionState("lastPublishTimestamp", null);
publishCountState = initContext.addClientConnectionState("publishCount", 0);
}Creating Additional Messages
Transformation scripts can create and publish additional MQTT messages during their execution. The topics and payloads of the messages created can vary from the messages may have different topics and payloads than the original message.
This feature enables various use cases, including conditionally publishing messages, fanning out messages to multiple topics, and publishing the same message in multiple data formats.
Branches
addBranch Function
The addBranch function of the InitContext object specifies that a transformation script intends to publish additional messages on a branch with the provided ID.
A script can only be used in a data policy operation if there is a corresponding onBranch object for every branch ID that the script declares.
In HiveMQ Edge, the addBranch function returns a Branch object.
| Field | Type | Description |
|---|---|---|
|
String |
The ID of the branch. |
After a branch has been added, it can be accessed in the transform function through the context.branches object.
Branch Object
The Branch object has a single addPublish method to publish new MQTT messages to the pipeline of the branch in a data policy.
| Field | Type | Description |
|---|---|---|
|
Function |
The |
addPublish Function
The addPublish function is a method of the Branch object.
It creates a new MQTT PUBLISH message to be published on the named branch.
| Field | Type | Description |
|---|---|---|
|
An object that represents an MQTT PUBLISH object. The same requirements apply to this value as to the |
The Data Hub Context object provides access to all of the Branch
objects defined in the init function of the script.
Within the transform function, you can use the context.branches["branchName"] to access a specific branch.
The addPublish function can then be used on this Branch object to create messages.
addPublish function with multiple branchesfunction init(initContext) {
initContext.addBranch('myBranch1');
initContext.addBranch('myBranch2');
}
function transform(publish, context) {
myBranch1 = context.branches['myBranch1'];
myBranch2 = context.branches['myBranch2'];
myBranch1.addPublish({
payload: { value: 1 },
topic: 'new/topic/1',
});
myBranch1.addPublish({
payload: { value: 2 },
topic: 'new/topic/1',
});
myBranch2.addPublish({
payload: { value: 3 },
topic: 'new/topic/2',
qos: 2,
});
return publish;
}In this example transformation script, two branch IDs are specified: myBranch1 and myBranch2.
The Branch objects can be accessed using context.branches.
When the script is executed, three new messages are created in total.
After a transformation script has finished, the Publish object the transform function returns becomes the new message for any following operations in the pipeline of the data policy.
However, newly created messages do not continue on this pipeline and instead must be redirected to a separate pipeline associated with the branchId specified in the addBranch function.
In order for a transformation script to publish additional messages to a given branch, the data policy where the script is used must define this pipeline with a matching branchId.
For more information, see Branches in Data Policies.
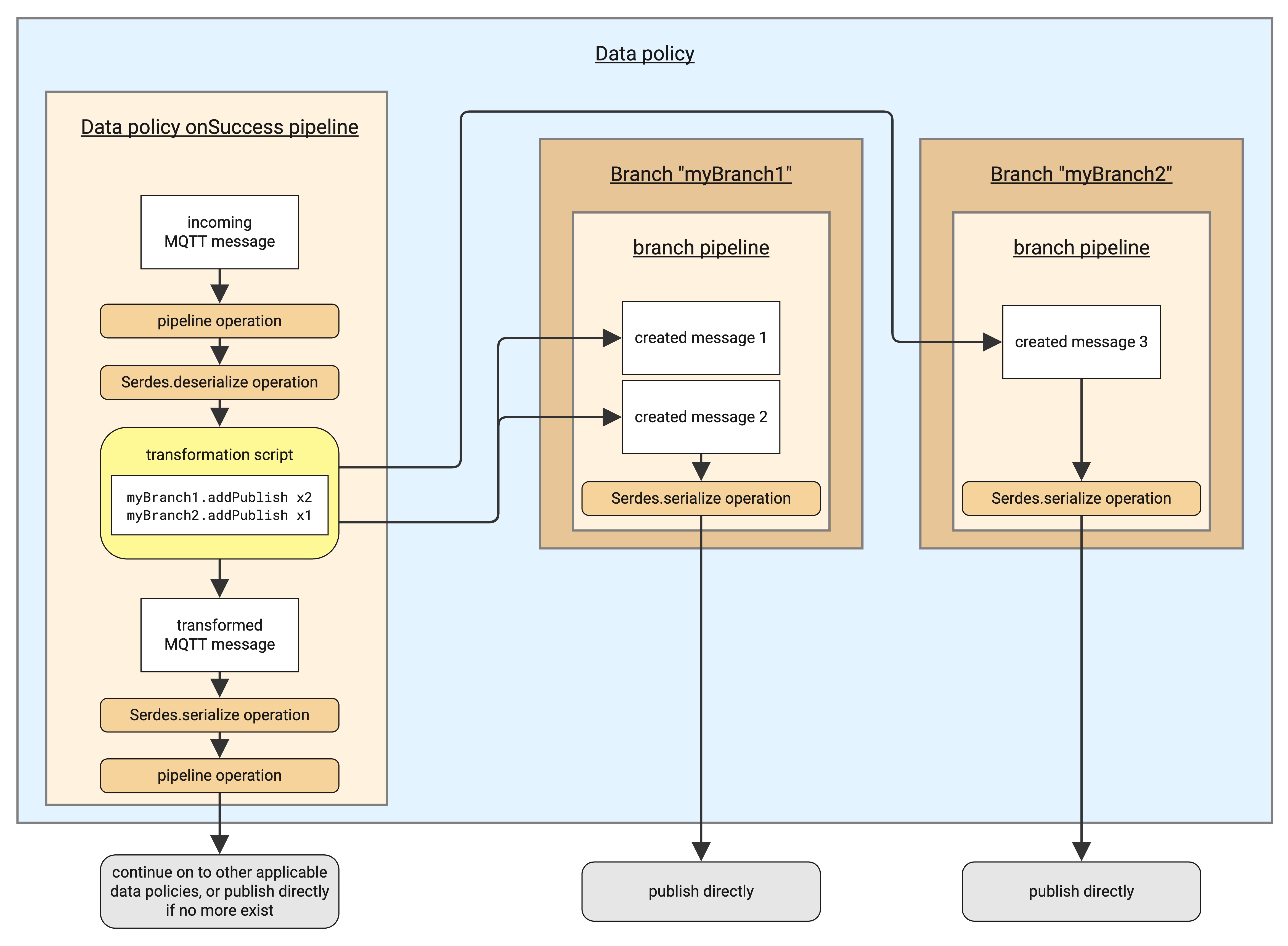
In the above diagram, a data policy defines pipelines for two branches named myBranch1 and myBranch2.
The branchId values match those defined in the init function of the example transformation script.
During the execution of the transform function for the incoming message, the script creates two new messages on the myBranch1 branch and one new message on the myBranch2 branch.
Sparkplug Metric Fan-out Example
function init(initContext) {
initContext.addBranch('metricsBranch');
}
function transform(publish, context) {
const metrics = publish.payload.metrics;
metrics.forEach( metric => {
const metricPublish = {
topic: publish.topic + '/' + metric.metricName,
payload: metric
}
context.branches['metricsBranch'].addPublish(metricPublish);
});
return publish;
}The script iterates over the metrics array and adds one new message per metric to the metricsBranch branch.
Each new message has an updated topic and a payload that contains one element of the metrics array.
After execution, the original publish is returned unmodified. A Data Hub data policy defines how further processing of new messages in the branches is handled.
| If you use Sparkplug workloads in your HiveMQ deployment, be sure to check out our new Sparkplug Module for Data Hub. For more information, see Data Hub Modules. |
Publish message for temperature violation (filtering)
function init(initContext) {
initContext.addBranch('violations');
}
function transform(publish, context) {
const temperatureThreshold = context.arguments.temperatureThreshold;
const payload = publish.payload;
if (payload.temperature > temperatureThreshold) {
// a new message about violation is created and published
const message = { 'topic': publish.topic + '/exceeded', payload: payload };
context.branches['violations'].addPublish( message );
}
return publish;
}The function in the example creates a new message when the temperature field exceeds the predefined threshold.
The threshold is defined in a data policy and is provided via arguments.
New messages are added to the
violations branch.
The handling of the new messages is defined in the data policy.
Stateful Transformations
Transformation scripts can be configured to store and retain states across multiple executions. This is useful when information about previously received messages must be known.
Example use cases:
-
Calculating the average of a payload value.
-
Maintaining a counter of how many messages have been received.
-
Calculating publish rates over a given time interval.
Client Connection State
Client connection state is a method of storing information across multiple executions of a transformation script on a per-client connection basis.
addClientConnectionState Function
The addClientConnectionState method of the InitContext object defines a state that can be used to store persistent data across multiple executions of a transformation script for a given MQTT client connection.
The addClientConnectionState function has the signature (stateId: string, defaultValue: any) => ClientConnectionState.
The arguments of the function are defined as follows:
| Field | Type | Description |
|---|---|---|
|
String |
The name of the state. |
|
Any |
The initial value of the state for new client connections. This must be a JSON-serializable value. |
Client connection states must be configured in the init function of a transformation script before they can be used.
function init(initContext) {
initContext.addClientConnectionState("publishCount", 0);
initContext.addClientConnectionState("payloadStatistics", {
maxValue: null,
minValue: null,
});
}ClientConnectionState Object
| Field | Type | Description |
|---|---|---|
|
Function |
Retrieves the current value of the state. This function can only be used within the |
|
Function |
Sets the current value of the state. This function can only be used within the |
The get and set methods operate on the state for the current MQTT client.
This is the client which sent the message currently being processed by the transform function.
The get method signature is () => any.
It returns the current value of the state.
The set method signature is (value: any) => void.
It modifies the current value of the state.
The value passed to this function must be JSON-serializable.
There is an upper limit on the allowed size of the state value.
For more information, see Scripting Requirements and Limitations.
If an error occurs while calling the set method, for example because an invalid value is passed, the state is not modified.
The type of a state value is not fixed and may be dynamically changed by the script.
let state1;
function init(initContext) {
state1 = initContext.addClientConnectionState("state1", null);
}
function transform(publish, context) {
const currentValue = state1.get();
if (publish.payload.type === 'string') {
state1.set('a string');
} else if (publish.payload.type === 'number') {
state1.set(42);
} else if (publish.payload.type === 'boolean') {
state1.set(true);
}
return publish;
}
Directly modifying the value the get method returns will not have any effect on the state.
You must use the set method to store your changes.
|
Client Connection State Lifecycle
When an MQTT client connects, its states are initialized to their specified defaultValue.
Transformation scripts can define the default value for a state using the second parameter of the addClientConnectionState function.
The client connection state is not shared between different MQTT clients. When the client disconnects, stored values are cleared. This also means that the state does not persist after a broker shutdown.
| States are not shared between scripts or between different versions of the same script. When you update a transformation script to a newer version, the state stored in the previous version is not retained. |
| When using client connection state with the data combining feature of HiveMQ Edge, state is persisted across reboots. The "client" in this case is the Edge protocol adapter itself, so its state remains until it the protocol adapter is deleted. |
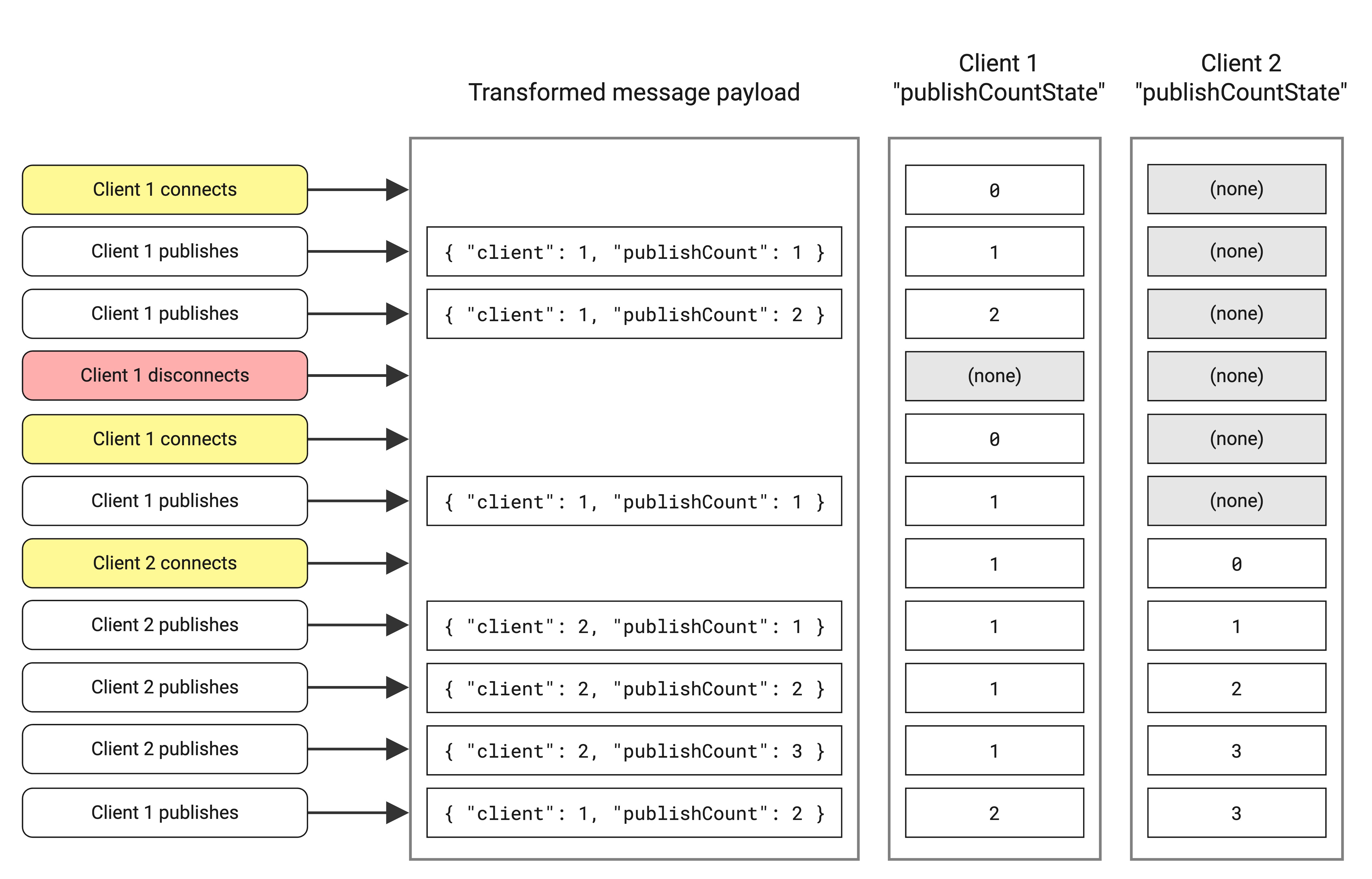
In the following example scenario, a transformation script keeps track of the total number of publishes received for each client and adds it to the transformed payload of publishes sent by the client. After client 1 disconnects, its stored state is reset.
function init(initContext) {
initContext.addClientConnectionState('publishCountState', 0);
}
function transform(publish, context) {
let currentPublishCount = context.clientConnectionStates.publishCountState.get();
currentPublishCount += 1;
context.clientConnectionStates.publishCountState.set(currentPublishCount);
return {
...publish,
payload: { client: context.clientId, publishCount: currentPublishCount },
};
}
Scripting Requirements and Limitations
Because JavaScript is a dynamically typed scripting language, the performance of transformation scripts will usually be slower than those of extensions.
Performing computationally expensive tasks such as decompression or data parsing within transformation scripts can impact the ability of Data Hub to process messages.
You can monitor your resource consumption levels with built-in Data Hub metrics.
For more information, see Data Hub metrics for HiveMQ Enterprise Edition and Data Hub metrics for HiveMQ Edge.
The maximum number of Data Hub scripts per HiveMQ Data Hub deployment is 5000 and the maximum source size per Data Hub script is 100kB.
|
| The maximum size of a single client connection state value is 10kB. The global limit for all state values stored in Data Hub at a given time is 50MB. |
Log messages for the script engine and from console.log are written into a script.log log file.
|
JSON-serializable values
All JavaScript values that are passed into and out of transformation scripts are converted into JSON strings.
This includes Publish objects and state values passed to ClientConnectionState.set.
However, not all datatypes in JavaScript can be converted to JSON.
The following JavaScript types are JSON-serializable:
-
Strings, for example,
"hello" -
Numbers, for example,
42,0.05 -
Booleans, for example,
true -
Arrays, for example,
[1, 2, 'hello'] -
Objects, for example,
{ x: 1, y: 2 },{ "a": { "b": "c" } } -
Null, for example,
null
BigInts, functions, classes such as Map and Date, Symbol, circular references, and other non-primitive JavaScript values are not supported.
Attempting to use these values when a JSON-serializable value is expected can cause data loss or execution errors.
|
The payload of a Publish object may be any JSON-serializable value in HiveMQ Edge. In HiveMQ Enterprise 4.37 and earlier, it must be an object. For example, { "hello": "world" } is acceptable as a payload value but "world" is not.
|
Example Transformation Scripts
Here are some common examples of how to use the transformation functions in typical IoT scenarios.
Naturally, you can adapt the functions according to your individual needs.
Add a payload field
This example shows how to add a new field to incoming MQTT message payloads.
function transform(publish, context) {
publish.payload.timestamp = new Date().toJSON();
return publish;
}In this example, a new field called timestamp with the current date is added to the message payload.
Restructure the message payload
Transformation can also be used to reduce the structural complexity of a message payload:
function transform(publish, context) {
publish.payload = { "value": publish.payload.metrics.map( metric => metric.value ) };
return publish;
}| The transform script assumes that the incoming payloads contain the following structure: |
{
"metrics": [
{
"value": 1
},
{
"value": 5
},
{
"value": 100
}
]
}applying the script the following payload is generated:
{
"value": [
1,
5,
100
]
}Compute a payload field
This example builds on the array of values from the previous Restructure the payload example.
Here, we want to compute statistical properties from the array.
function transform(publish, context) {
publish.payload.max = Math.max( ...publish.payload.value );
publish.payload.min = Math.min( ...publish.payload.value );
publish.payload.avg = publish.payload.value.reduce( ( x, y ) => x + y, 0 ) / publish.payload.value.length;
return publish;
}The computation of the maximum, minimum, and average of the values yields the following payload:
{
"values": [
1,
5,
100
],
"max": 100,
"min": 1,
"avg": 35.333333333333336
}Rename a message payload field
In some cases, devices provide the same types of values but use different naming conventions.
The transformation function can be used to harmonize the incoming device data.
function getFieldsToRename() {
return [{ old: "Timestamp", new: "timestamp" }, { old: "temp", new: "temperature" } ];
}
function transform(publish, context) {
const payload = publish.payload;
getFieldsToRename().forEach( field => {
m[field.new] = m[field.old];
delete m[field.old]
} );
publish.payload = payload;
return publish;
}The script defines a global list of fields to be renamed.
In the example, from Timestamp to timestamp and from temp to temperature.
The function transform iterates through all fields, sets the new field name as specified where applicable, and deletes the old field.
Report a rolling average over a configurable time window
| This example uses features that are currently only available in HiveMQ Edge. |
The following transformation script collects the payload values a client publishes and calculates the average value and publish rate over a specified period. The average value, publish rate, and corresponding MQTT client ID are periodically published to a separate topic.
let averageReportBranch, historyState;
function init(initContext) {
averageReportBranch = initContext.addBranch('averageReport');
historyState = initContext.addClientConnectionState('history', {
values: [],
lastReportTime: 0,
});
}
function transform(publish, context) {
const currentTimeMs = Date.now();
const history = historyState.get();
history.values.push({
value: publish.payload.value,
timestamp: currentTimeMs,
});
// The averaging time window and reporting frequency can be configured using the `arguments` field in the data policy.
const averageIntervalMs = context.arguments.averageIntervalMs;
const reportIntervalMs = context.arguments.reportIntervalMs;
const reportNeeded = currentTimeMs > history.lastReportTime + reportIntervalMs;
if (reportNeeded) {
// Remove values older than the specified interval.
const cutoffTime = currentTimeMs - averageIntervalMs;
history.values = history.values.filter(entry => entry.timestamp >= cutoffTime);
// Calculate the average
const valueSum = history.values.map(entry => entry.value).reduce((a, b) => a + b);
const valueAverage = valueSum / history.values.length;
const publishFrequencyPerSecond = (valueSum / averageIntervalMs) / 1000;
const reportPayload = {
clientId: context.clientId,
average: valueAverage,
frequencyPerSecond: publishFrequencyPerSecond,
};
averageReportBranch.addPublish({
topic: publish.topic + '/report',
payload: reportPayload,
});
}
return publish;
}It expects messages with payloads in the following format:
{
"value": 42
}It publishes new messages with the following payload structure on the branch averageReport:
{
"clientId": "client1",
"average": 14.6,
"frequencyPerSecond": 0.8
}The averaging time window and reporting frequency can be configured using the arguments provided to the transformation script.
Script Management from the HiveMQ Control Center
The Data Hub Script view in the HiveMQ Control Center facilitates your script management with an intuitive user interface. Our script creation wizard offer an intuitive way to create new scripts with context-sensitive help and immediate feedback on configuration validity.
For more information, see HiveMQ Control Center.